

- 2023-7-10开始 2023-12-23搞定
- 还需要一个好点的总结,保证对所有知识都融会贯通,加油吧
- 搞完看一下jyy的课,常读常新
- lab代码
Lab1
配置项目环境
照着这个或者这个搭建一遍就OK,此外要跑测试的话可能会找不到python环境,配置一下软链接就行,记住一定要用fetch再git checkout lab_name的方式建立,不要自己建立新的branch,一些文件可能会存在问题!!!
配置编码环境
项目是使用makefile进行组织编译的,采用交叉编译,如果直接用vscode打开则不能跳转函数,不大方便,可以看jyy视频通过bear工具生成compile_commands.json文件,随后配置插件使之能够加载这个文件,从而可以保证函数跳转。但vscode用起来还是不舒服,配文件啥的很麻烦,我采用的方案是使用clion远程链接wsl(其实本地也能打开这个项目文件,但是解析compile_commands.json的时候由于路径是wsl路径所以会出问题,因此使用remote方案),首先bear make qemu编译完成后退出,生成compile_commands.json文件,clion选择打开即可,打开的时候要选择compilation database项目,如此就可以随便跳转了,其他可以参考一下这个使clion支持makefile项目。
妈的现在发现clion连wsl写中文注释会出现代码高亮失效的情况,而且卡得一批,还是用vscode+clangd组合吧,参考这个,注意.h文件有问题得自己手动搞,.clang-format参考这个老哥的
系统调用

sleep
使用系统调用int sleep(int)封装一下就行,最终还是使用汇编来调用kernel层中最基础的sys_sleep,注意特殊情况如的处理。另外还需要注意,C语言整个编译过程要保证定义只有一次,这里想用user/ulib.c中的atoi函数,导入ulib.c会造成重复编译,直接在文件里声明atoi函数即可。写完之后要在Makefile里加上对应的文件名。代码如下:
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4
5int atoi(const char *s);
6
7int main(int argc, char *argv[])
8{
9 if (argc <= 1)
10 {
11 fprintf(2, "sleep: please set up sleep time\n");
12 exit(1);
13 }
14 if (argc > 2)
15 {
16 fprintf(2, "sleep: too many arguments\n");
17 exit(1);
18 }
19 sleep(atoi(argv[1]));
20 exit(0);
21}
pingpong
要知道,pipe可以在进程间通信,随后只需要两个pipe,一个负责从父进程向子进程传输数据,一个负责从子进程向父进程传输数据,先写后读,关闭对应的pipe端即可。代码如下:
1#include "kernel/types.h"
2#include "user/user.h" // fork
3
4int main(int argc, char *argv[])
5{
6 char buffer[5];
7 if (argc > 1)
8 {
9 fprintf(2, "pingpong: too many arguments");
10 }
11 int parent_to_child[2];
12 int child_to_parent[2];
13 // trans data from parent to child
14 pipe(parent_to_child);
15 // trans data from child to parent
16 pipe(child_to_parent);
17
18 if (fork() == 0)
19 {
20 // child process
21 // close write end of parent to child;
22 close(parent_to_child[1]);
23 // close read en of child to parent;
24 close(child_to_parent[0]);
25 write(child_to_parent[1], "pong\n", 5);
26 // close write end of child to parent
27 close(child_to_parent[1]);
28 read(parent_to_child[0], buffer, sizeof(buffer));
29 // close read end of parent to child
30 close(parent_to_child[1]);
31 printf("%d: received ", getpid());
32 write(1, buffer, 5);
33 }
34 else
35 {
36 // parent process
37 // close read end of parent to child
38 close(parent_to_child[0]);
39 // close write end of child to parent
40 close(child_to_parent[1]);
41 write(parent_to_child[1], "ping\n", 5);
42 // close write end of parent to child
43 close(parent_to_child[1]);
44 read(child_to_parent[0], buffer, sizeof(buffer));
45 // close read end of child to parent
46 close(child_to_parent[0]);
47 printf("%d: received ", getpid());
48 write(1, buffer, 5);
49 }
50 exit(0);
51}
primes
首先还得看懂教程提示:从2-35依次送往pipe读端,然后循环创建进程处理每一次丢弃后的数据。此外,要时刻记住三件事:
- 把握数据的流向
- 关闭不用的pipe的所有的读端和写端,否则会阻塞
- 数据在pipe中是单向流动的 代码如下:
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4
5void prime(int read_pipe, int write_pipe, int divider)
6{
7 int num;
8 while (read(read_pipe, &num, sizeof(int)) != 0)
9 {
10 if (num % divider != 0)
11 {
12 write(write_pipe, &num, sizeof(int));
13 }
14 }
15 close(read_pipe);
16 close(write_pipe);
17
18 exit(0);
19}
20
21#define MAX 35
22
23int main()
24{
25 int p[2];
26 pipe(p);
27
28 if (fork() == 0)
29 {
30 close(p[0]);
31 // child process 0: write all number to pipe
32 for (int i = 2; i <= MAX; i++)
33 {
34 write(p[1], &i, sizeof(int));
35 }
36 close(p[1]);
37 exit(0);
38 }
39
40 int num;
41 int read_pipe = p[0];
42 int write_pipe;
43 close(p[1]);
44
45 while (read(read_pipe, &num, sizeof(int)) != 0)
46 {
47 int p_next[2];
48 pipe(p_next);
49 write_pipe = p_next[1];
50
51 if (fork() == 0)
52 {
53 // child process
54 printf("prime %d\n", num);
55 // read data and send prime to the next pipe
56 prime(read_pipe, write_pipe, num);
57 close(read_pipe);
58 close(write_pipe);
59 close(p_next[0]);
60 // close this process
61 exit(0);
62 }
63 else
64 {
65 // father process
66 close(read_pipe);
67 close(write_pipe);
68 read_pipe = p_next[0];
69 }
70 }
71 // father: close read end
72 close(read_pipe);
73 wait(0);
74 exit(0);
75}
find
写一个find函数,真是踩了太多坑了,一开始写出来了,但是不清楚为什么需要按一下回车才能执行结果,苦苦debug了很久,gdb也有bug,明明在find.c的main打的断点,用一下ls居然也触发了,真是吃屎。最后灵感迸发,把while里面的if的判断条件换了个位置就可以不用按回车了。 解决思路也很简单,先判断是目录还是文件,是文件就对比,是目录就递归调用,这里需要注意:
- 有时候测试卡住了跑一下make clean就可以
- 注意./gdb_init里的端口设置,保证能够连接
- 注意端口占用,有时候会有程序不知不觉占用25000端口导致gdb不可用
- 注意函数的行为,如fstat、stat、strlen、strcpy、strcmp等函数的行为
- 一些边界情况也要写全,不要不写
- makefile和gdb等工具还是要学一下,不然一大堆事情 代码如下:
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4#include "kernel/fs.h"
5
6// recusively find file_name in path
7// path is directory by default
8void find(char* path, char* file_name)
9{
10 char buf[512], *p;
11 int fd; // file descriptor
12 struct stat st;
13 struct dirent de;
14 if ((fd = open(path, 0)) < 0)
15 {
16 fprintf(2, "find: cannot open %s\n", path);
17 return;
18 }
19 if (fstat(fd, &st) < 0)
20 {
21 fprintf(2, "find: cannot open %s\n", path);
22 close(fd);
23 return;
24 }
25 if(st.type == T_FILE)
26 {
27 fprintf(2, "find: please enter directory path\n");
28 close(fd);
29 return;
30 }
31 if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf)
32 {
33 printf("find: path too long\n");
34 close(fd);
35 return;
36 }
37 strcpy(buf, path);
38 p = buf + strlen(buf);
39 *p++ = '/';
40 // read from directory,every time read a dirent
41 while (read(fd, &de, sizeof(de)) == sizeof(de))
42 {
43 if((de.inum == 0) || (strcmp(de.name, ".") == 0) || (strcmp(de.name, "..") == 0))
44 continue;
45 memmove(p, de.name, DIRSIZ);
46 p[DIRSIZ] = 0; // add end mark
47 if(stat(buf, &st) < 0)
48 {
49 printf("ls: cannot stat %s\n", buf);
50 continue;
51 }
52 if (st.type == T_DIR)
53 {
54 // if path is a directory, continue to recursion
55 find(buf, file_name);
56 }
57 else
58 {
59 // if path is a file, then compare it with file name
60 if (strcmp(de.name, file_name) == 0)
61 {
62 fprintf(1, "%s\n", buf);
63 continue;
64 }
65 }
66 }
67 close(fd);
68 return;
69 // exit(0);
70}
71
72int main(int argc, char *argv[])
73{
74 if (argc < 3)
75 {
76 fprintf(2, "find: please enter enough arguments\n");
77 exit(1);
78 }
79 if (argc > 3)
80 {
81 fprintf(2, "find: too many arguments\n");
82 exit(1);
83 }
84 find(argv[1], argv[2]);
85 exit(0);
86}
xargs
xargs是拿到上一个指令的输出,并且按照一定的规则(-n)塞给下一个指定程序(作为xargs的参数),如:
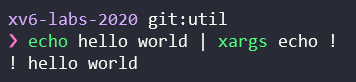
注意获取数据是从标准输入获取,因为不知道大小只能获取一个字符,如果获取到了换行符则认为是一组参数,很简单,用到了一点K&R的读取技巧。随后使用fork和exec进行执行,非常简单,完整代码如下:
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4#include "kernel/param.h"
5
6int main(int argc, char *argv[])
7{
8 char *argv_real[MAXARG];
9 char tmp = 0;
10 char arg[MAXARG]; // store arg passed by pipe
11 int index = 0;
12
13 if (argc < 2)
14 {
15 fprintf(2, "xargs: more arguments required!");
16 }
17 if (argc > MAXARG - 1)
18 {
19 fprintf(2, "xargs: too many arguments!");
20 }
21
22 for (int i = 0; i < argc - 1; i++)
23 {
24 argv_real[i] = argv[i + 1];
25 }
26
27 while (read(0, &tmp, sizeof(tmp)) != 0)
28 {
29 if (index == MAXARG - 1)
30 {
31 fprintf(2, "xargs: argument is too long");
32 }
33 if (tmp != '\n')
34 {
35 arg[index++] = tmp;
36 }
37 else
38 {
39 arg[index] = '\0';
40 index = 0;
41 // fork and exec
42 if (fork() == 0)
43 {
44 argv_real[argc - 1] = arg;
45 exec(argv_real[0], argv_real);
46 exit(0);
47 }
48 else
49 {
50 // wait for child process
51 wait(0);
52 }
53 }
54 }
55 exit(0);
56}
Lab2
sys_trace
设计一个sys_trace系统调用,这里有很多需要注意的地方,首先是执行流程:
- 在user.h添加一个void trace(int)的函数原型,然后在usys.pl中添加entry(“trace”),usys.pl会通过脚本生成一堆汇编代码(user/usys.S),生成下面这段代码:
1.global trace
2trace:
3 li a7, SYS_trace
4 ecall
5 ret
作用就是声明一个全局的代码段,当trace函数被调用时,执行该程序,该程序将SYS_trace(一个由kernel/syscall.h中定义的宏)传入到a7中,随后执行ecall,ecall的含义比较复杂,暂且不知道,但一点是肯定的,它会带着数据执行syscall!
-
ecall则会整理数据后跳转到syscall函数(kernel/syscall.c),根据SYS_trace决定执行数组中的对应的函数,在此例中则是sys_trace系统调用(kernel/sysproc.c)
-
在sys_trace系统调用中采用argint函数获取trace函数传入的参数,并将其赋值给trace_mask(kernel/proc.h),系统调用执行完毕后返回syscall打印题目要求的输出。
执行流程有点麻烦,其中最让人疑惑的就是参数从trace传递到sys_trace,目前不知道用了什么手段,但应该是把数据存在某些地方。 具体来说要做的事情有:
- 在user/user.h中添加trace函数的原型:
1int trace(int); // 返回值要和sys_trace保持一致,输入不用
- 在kernel/syscall.h中添加宏定义,即系统调用的标号
1#define SYS_trace 22
- 在user/usys.pl中添加entry,建立trace和SYS_trace的关联
1entry("trace");
- 在kernel/sysproc.c中添加sys_trace函数,函数原型要与其他函数保持一致,便于syscall统一调用
1uint64 sys_trace(void)
2{
3 int mask;
4 if (argint(0, &mask) < 0) // 这里不太明白从哪里读的
5 {
6 return -1;
7 }
8 // set trace mask
9 struct proc *p = myproc();
10 p->trace_mask = mask;
11
12 return 0;
13}
- 在kernel/syscall.c的函数数组中添加
[SYS_trace] sys_trace,并在前面加上extern声明,这是C的语法,指定下标元素的值;添加id与名字对应的数组:
1const char *syscall_name[] = {
2 [SYS_fork] "fork",
3 [SYS_exit] "exit",
4 [SYS_wait] "wait",
5 [SYS_pipe] "pipe",
6 [SYS_read] "read",
7 [SYS_kill] "kill",
8 [SYS_exec] "exec",
9 [SYS_fstat] "fstat",
10 [SYS_chdir] "chdir",
11 [SYS_dup] "dup",
12 [SYS_getpid] "getpid",
13 [SYS_sbrk] "sbrk",
14 [SYS_sleep] "sleep",
15 [SYS_uptime] "uptime",
16 [SYS_open] "open",
17 [SYS_write] "write",
18 [SYS_mknod] "mknod",
19 [SYS_unlink] "unlink",
20 [SYS_link] "link",
21 [SYS_mkdir] "mkdir",
22 [SYS_close] "close",
23 [SYS_trace] "trace",
24};
- 在kernel/proc.h中添加trace_mask来记录数据
1// Per-process state
2struct proc {
3 struct spinlock lock;
4
5 // p->lock must be held when using these:
6 enum procstate state; // Process state
7 struct proc *parent; // Parent process
8 void *chan; // If non-zero, sleeping on chan
9 int killed; // If non-zero, have been killed
10 int xstate; // Exit status to be returned to parent's wait
11 int pid; // Process ID
12
13 int trace_mask;
14
15 // these are private to the process, so p->lock need not be held.
16 uint64 kstack; // Virtual address of kernel stack
17 uint64 sz; // Size of process memory (bytes)
18 pagetable_t pagetable; // User page table
19 struct trapframe *trapframe; // data page for trampoline.S
20 struct context context; // swtch() here to run process
21 struct file *ofile[NOFILE]; // Open files
22 struct inode *cwd; // Current directory
23 char name[16]; // Process name (debugging)
24};
- 在kernel/syscall.c中的syscall函数中添加行为,检测当前系统调用和开启trace的系统调用是否一致,如果一致则打印信息:
1void syscall(void)
2{
3 int num;
4 struct proc *p = myproc();
5
6 num = p->trapframe->a7;
7 if (num > 0 && num < NELEM(syscalls) && syscalls[num])
8 {
9 p->trapframe->a0 = syscalls[num]();
10
11 if ((p->trace_mask & (1 << num)) != 0)
12 {
13 // open trace
14 printf("%d: syscall %s -> %d\n", p->pid, syscall_name[num], p->trapframe->a0);
15 }
16 }
17 else
18 {
19 printf("%d %s: unknown sys call %d\n",
20 p->pid, p->name, num);
21 p->trapframe->a0 = -1;
22 }
23}
- 在user中添加trace.c文件来执行:
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4#include "kernel/param.h"
5
6int main(int argc, char *argv[])
7{
8 if (argc < 2)
9 {
10 fprintf(2, "trace: wrong number of arguments!\n");
11 exit(1);
12 }
13
14 int mask = atoi(argv[1]);
15 char *argv_real[MAXARG];
16
17 trace(mask);
18
19 for (int i = 0; i < argc - 2; i++)
20 {
21 argv_real[i] = argv[i + 2];
22 }
23
24 if (fork() == 0)
25 {
26 exec(argv_real[0], argv_real);
27 }
28 else
29 {
30 wait(0);
31 }
32 exit(0);
33}
还有一些关于debug的部分比较重要,网友解释,主要是要了解gdb是通过file操作来读取最终生成的可执行文件或者说ELF(Executable and Linkable Format),后续的所有打断点都是基于ELF文件来的,有时候解释不了就没有办法打断点。
sys_sysinfo
妈的这个系统调用一定要叫sysinfo,不然会出错
- 还是和上个实验一样增加一些前置定义
- 主要目的是统计free memory和used process,那么第一步就是寻找free memory的数量,根据提示可以在kernel/kalloc.c中看到kalloc函数,里面有个kmem的结构体,freelist应该就是链表,存储所有空闲的pagesize的内存,指向的地方是空闲的4096大小的内存的首地址,那么后续就和普通链表操作一样,统计一共有多少page:
1// return free memory in bytes
2uint64 get_free_memory(void)
3{
4 struct run *r;
5
6 uint64 count = 0;
7 acquire(&kmem.lock);
8 r = kmem.freelist;
9 while (r)
10 {
11 r = r->next;
12 ++count;
13 }
14 release(&kmem.lock);
15 return count * PGSIZE;
16}
- 下一步是找到已经使用的进程的数量,根据提示可以在kernel/proc.c中看到一个allocproc的函数,里面的行为正是从proc数组中获取状态,如果不是UNUSED那么就将其纳入统计,代码如下:
1// get processes whose state is not UNUSED
2uint64 get_used_process(void)
3{
4 struct proc *p;
5 uint64 count = 0;
6 for (p = proc; p < &proc[NPROC]; p++)
7 {
8 acquire(&p->lock);
9 if (p->state != UNUSED)
10 {
11 ++count;
12 }
13 release(&p->lock);
14 }
15 return count;
16}
- 写sys_sysinfo系统调用,这里面要尤其注意,获取的参数是地址,但这个地址实际上是用户态的栈空间中的地址,内核态时似乎不允许直接访问,这里需要先获取用户空间中sysinfo结构体的地址,再构建一个临时的sysinfo对象存储数据,再使用copyout函数从内核空间将数据复制到用户空间,代码如下:
1extern uint64 get_free_memory(void);
2extern uint64 get_used_process(void);
3
4uint64 sys_sysinfo(void)
5{
6 uint64 info;
7 struct sysinfo p_sysinfo;
8
9 struct proc *p = myproc();
10 // 这里获取的info是用户空间的虚拟地址,直接读写根本就不行,因为此时在内核空间,很容易搞崩
11 if (argaddr(0, &info) < 0)
12 {
13 return -1;
14 }
15
16 p_sysinfo.freemem = get_free_memory();
17 p_sysinfo.nproc = get_used_process();
18 // pagetable就是用户空间的数据,info则是虚拟目标地址,第三个则是源地址(内核空间),第四个就是需要复制的字节数量!
19 if (copyout(p->pagetable, info, (char *)&p_sysinfo, sizeof(p_sysinfo)) < 0)
20 {
21 return -1;
22 }
23 return 0;
24}
这里一定一定要注意,用户空间和内核空间的地址不是一样的,在内核态访问用户空间的地址会直接把内核搞崩溃!
Lab3
vmprint
实现一个vmprint的函数,遍历三层page_table树
- 在kernel/vm.c中增加vmprint函数,首先打印该地址,随后遍历打印三层
1void vmprint(pagetable_t pagetable)
2{
3 printf("page table %p\n", pagetable);
4 vmprint_recursively(pagetable, 1);
5}
- 遍历函数实现,本质上就是循环加遍历,CS106B有用的,抄一下freewalk函数就OK
1void vmprint_recursively(pagetable_t pagetable, int depth)
2{
3 for (int i = 0; i < 512; i++)
4 {
5 pte_t pte = pagetable[i];
6 if (pte & PTE_V)
7 {
8 for (int j = 0; j < depth; j++)
9 {
10 if (j == 0)
11 {
12 printf("..");
13 }
14 else
15 {
16 printf(" ..");
17 }
18 }
19 printf("%d: pte %p pa %p\n", i, pte, PTE2PA(pte));
20 if ((pte & (PTE_R | PTE_W | PTE_X)) == 0)
21 {
22 vmprint_recursively((pagetable_t)PTE2PA(pte), depth + 1);
23 }
24 }
25 }
26}
- 在kernel/defs.h中增加vmprint声明,在exec.c/exec中调用
1if (p->pid == 1)
2 vmprint(p->pagetable);
这个实验倒是很简单,主要思路在freewalk函数里就有。
A kernel page table per process
其实这个实验是和下一个实验进行配合,对内核进行一点魔改,自始至终xv6都是通过SATP寄存器存储pagetable,进而对虚拟内存进行寻址找出真正的地址,在内核态SATP存储kernel pagetable而在用户态存储每个进程的pagetable即user pagetable,也就是说内核有pagetable,进程也有pagetable。这种情况就会造成用户态的地址在进入内核态后没用,因此这部分实验和后面的一个实验就是让每个进程都有一份kernel pagetable,进入内核态时不再使用全局的kernel pagetable,而是使用自己的,来达到让每个进程都能够便捷的使用自己的虚拟内存。
内核也是C程序,只不过是用来管理其他程序的C程序,一方面提供一些系统调用的接口,来使得其他程序能够便捷地与硬件沟通,另一方面还要管理其他程序的生命周期,为程序分配进程,回收进程。在分配方面,exec程序很重要,这个程序读取并检查可执行文件了ELF头,将程序加载进内存替换当前的进程的数据
- 在kernel/proc.h中的proc结构体中增加字段kernel_pagetable,用来映射内核
1// Per-process state
2struct proc {
3 struct spinlock lock;
4
5 // p->lock must be held when using these:
6 enum procstate state; // Process state
7 struct proc *parent; // Parent process
8 void *chan; // If non-zero, sleeping on chan
9 int killed; // If non-zero, have been killed
10 int xstate; // Exit status to be returned to parent's wait
11 int pid; // Process ID
12
13 // these are private to the process, so p->lock need not be held.
14 uint64 kstack; // Virtual address of kernel stack
15 uint64 sz; // Size of process memory (bytes)
16 pagetable_t pagetable; // User page table
17 pagetable_t kernel_pagetable;// lab 3
18 struct trapframe *trapframe; // data page for trampoline.S
19 struct context context; // swtch() here to run process
20 struct file *ofile[NOFILE]; // Open files
21 struct inode *cwd; // Current directory
22 char name[16]; // Process name (debugging)
23};
- 对于每个进程都需要一份kernel pagetable,因此需要一个函数来执行和kvminit函数相似的功能,本质上这就是对同一份物理地址进行多次映射,也就是说有多份虚拟地址指向同一份物理地址:
1pagetable_t get_kpt()
2{
3 pagetable_t kpt = (pagetable_t) kalloc();
4 if (kpt == 0) {
5 return 0;
6 }
7 memset(kpt, 0, PGSIZE);
8 ukvmmap(kpt, UART0, UART0, PGSIZE, PTE_R | PTE_W);
9 ukvmmap(kpt, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
10 ukvmmap(kpt, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
11 ukvmmap(kpt, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
12 ukvmmap(kpt, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
13 ukvmmap(kpt, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
14 ukvmmap(kpt, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
15 return kpt;
16}
- 有了函数之后还需要在kernel/proc.c中的allocproc函数中进行调用,这个函数负责找出未使用的进程并返回,并且对这个进程struct来进行一些初始化(这玩意应该就是进程控制块),包括初始化kernel pagetable。
1static struct proc*
2allocproc(void)
3{
4...
5 // An empty user page table.
6 p->pagetable = proc_pagetable(p);
7 if(p->pagetable == 0){
8 freeproc(p);
9 release(&p->lock);
10 return 0;
11 }
12
13 // 这里就相当于初始化了
14 p->kernel_pagetable = get_kpt();
15 if (p->kernel_pagetable == 0)
16 {
17 freeproc(p);
18 release(&p->lock);
19 return 0;
20 }
21...
22}
- 在kernel/proc.c:procinit函数中会负责映射全局的kernel pagetable中的针对每个进程的kstack,因此在进程的kernel pagetable中也至少要映射自己,同样需要一个函数来实现这个过程 // map kernel pagetable per process with pa void ukvmmap(pagetable_t kpt, uint64 va, uint64 pa, uint64 sz, int perm) { if (mappages(kpt, va, sz, pa, perm) != 0) panic(“ukvmmap”); }
- 此时还需要在kernel/proc.c:allocproc中调用这个函数,调用之前要保证先有物理内存
1static struct proc*
2allocproc(void)
3{
4...
5 // 这里就相当于初始化了
6 p->kernel_pagetable = get_kpt();
7 if (p->kernel_pagetable == 0)
8 {
9 freeproc(p);
10 release(&p->lock);
11 return 0;
12 }
13 // 同时也整了块内存来放kstack,这个kstack实际上是自己的
14 char *pa = kalloc();
15 if (pa == 0)
16 panic("allocproc: kalloc");
17 uint64 va = KSTACK((int)(p - proc));
18 ukvmmap(p->kernel_pagetable, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
19 // 这个时候p->kstack指的就是kpt中的地址了
20 p->kstack = va;
21...
22}
- 现在初始化这个kernel pagetable已经完成了,但还需要在合适的地方使用这个东西(SATP寄存器),需要在kernel/proc.c:scheduler函数中对其进行调用,同时,如果没有进程被使用那么就可以直接调用全局的内核页表
1void
2scheduler(void)
3{
4 struct proc *p;
5 struct cpu *c = mycpu();
6
7 c->proc = 0;
8 for(;;){
9 // Avoid deadlock by ensuring that devices can interrupt.
10 intr_on();
11
12 int found = 0;
13 for(p = proc; p < &proc[NPROC]; p++) {
14 acquire(&p->lock);
15 if(p->state == RUNNABLE) {
16 // Switch to chosen process. It is the process's job
17 // to release its lock and then reacquire it
18 // before jumping back to us.
19 p->state = RUNNING;
20 c->proc = p;
21 w_satp(MAKE_SATP(p->kernel_pagetable));
22 sfence_vma();
23 swtch(&c->context, &p->context);
24
25 // Process is done running for now.
26 // It should have changed its p->state before coming back.
27 c->proc = 0;
28
29 found = 1;
30 }
31 release(&p->lock);
32 }
33#if !defined (LAB_FS)
34 if(found == 0) {
35 intr_on();
36 w_satp(MAKE_SATP(kernel_pagetable));
37 sfence_vma();
38 asm volatile("wfi");
39 }
40#else
41 ;
42#endif
43 }
44}
- 有了初始化,有了使用,下一个很自然的想法就是应该释放掉,毕竟内存是通过alloc来的,在free之前可以看看初始化的时候想想有哪些需要free的:
- 初始化的时候申请了一页kstack,那么这个需要被free掉
- 进程的内核页表本身用了一些空间来存储多级页表(在walk的时候分配的) 因此需要free以上这些东西,free kstack内存是很简单的,但是多级页表很麻烦,且不能free掉最终的物理内存,因为有其他的进程还在使用,所以需要一个函数来执行这个过程,实现需要参考freewalk函数,但切记不能free掉最终的物理内存。这里要注意,最后一级页表的RWX位肯定有一个为1,因此可以通过该种手段来判断是不是最后一级页表。(但感觉freewalk也是这么做的,感觉能直接用freewalk)
1void proc_freekpt(pagetable_t kpt)
2{
3 // kpt中有什么需要被free的?
4 // 无非是之前map的pa,但pa又不是freelist管理的,因此没有必要去清除
5 for (int i = 0; i < 512; i++)
6 {
7 pte_t pte = kpt[i];
8 // 该pte是有效的,可以被访问
9 if (pte & PTE_V)
10 {
11 kpt[i] = 0;
12 // 这代表当前页表项b
13 if ((pte & (PTE_R | PTE_W | PTE_X)) == 0)
14 {
15 uint64 child = PTE2PA(pte);
16 proc_freekpt((pagetable_t)child);
17 }
18 }
19 }
20 kfree((void *)kpt);
21}
因此最后只需要在freeproc函数中增加两部分即可
1static void
2freeproc(struct proc *p)
3{
4 if(p->trapframe)
5 kfree((void*)p->trapframe);
6 p->trapframe = 0;
7 // 删除kernel stack
8 if (p->kstack)
9 {
10 pte_t *pte = walk(p->kernel_pagetable, p->kstack, 0);
11 if (pte == 0)
12 panic("freeproc: kstack");
13 kfree((void *)PTE2PA(*pte));
14 }
15 if(p->pagetable)
16 proc_freepagetable(p->pagetable, p->sz);
17 // 删除kernel pagetable
18 if (p->kernel_pagetable)
19 proc_freekpt(p->kernel_pagetable);
20 p->pagetable = 0;
21 p->sz = 0;
22 p->pid = 0;
23 p->parent = 0;
24 p->name[0] = 0;
25 p->chan = 0;
26 p->killed = 0;
27 p->xstate = 0;
28 p->state = UNUSED;
29}
- 实际上还有最后一个地方需要更改,那就是kvmpa函数,这里想办法让它使用process的页表
1uint64
2kvmpa(uint64 va)
3{
4 uint64 off = va % PGSIZE;
5 pte_t *pte;
6 uint64 pa;
7
8 pte = walk(myproc()->kernel_pagetable, va, 0);
9 if(pte == 0)
10 panic("kvmpa");
11 if((*pte & PTE_V) == 0)
12 panic("kvmpa");
13 pa = PTE2PA(*pte);
14 return pa+off;
15}
Simplify copyin/copyinstr
3.2和3.2是搭配起来的,上面已经想办法让每个process都有自己的kernel pagetable,但这玩意没啥用,想要它真正起作用来达到在内核态时直接可以用虚拟地址就得想办法把每个process的pagetable映射到其kernel pagetable上,比上一个实验简单。这里需要做到的事情只有两件:
- 把pagetable映射到kernel pagetable,根据hints可以知道可以在不超过PLIC(0xc000000)的地方映射pagetable,毕竟虚拟内存从0开始,参考uvmcopy函数的实现,魔改一个自己的函数就行,注意这里需要install ptes而不是去mappage,同时要记住清除标志位。
1void
2uvmkptcopy(pagetable_t pagetable, pagetable_t kpagetable, uint64 oldsz, uint64 newsz)
3{
4 pte_t *pte_from, *pte_to;
5 uint64 a, pa;
6 uint flags;
7
8 if (newsz < oldsz)
9 return;
10
11 oldsz = PGROUNDUP(oldsz);
12 for (a = oldsz; a < newsz; a += PGSIZE)
13 {
14 if ((pte_from = walk(pagetable, a, 0)) == 0)
15 panic("u2kvmcopy: pte should exist");
16 if ((pte_to = walk(kpagetable, a, 1)) == 0)
17 panic("u2kvmcopy: walk fails");
18 pa = PTE2PA(*pte_from);
19 // 清除PTE_U的标记位
20 flags = (PTE_FLAGS(*pte_from) & (~PTE_U));
21 *pte_to = PA2PTE(pa) | flags;
22 }
23}
- 在正确的地方调用这个函数,什么是正确的地方,就是pagetable改变的地方,根据提示共有四处:exec()、fork()、sbrk()、userinit()
- exec()
1int
2exec(char *path, char **argv)
3{
4...
5 sp = sz;
6 stackbase = sp - PGSIZE;
7
8 // 复制
9 uvmkptcopy(pagetable, p->kernel_pagetable, 0, sz);
10...
11}
- fork()
1int
2fork(void)
3{
4...
5 uvmkptcopy(np->pagetable, np->kernel_pagetable, 0, np->sz);
6
7 safestrcpy(np->name, p->name, sizeof(p->name));
8...
9}
- sbrk(),这里要注意这个是个系统调用,真正需要添加的地方在growproc函数中
1int
2growproc(int n)
3{
4 uint sz;
5 struct proc *p = myproc();
6
7 sz = p->sz;
8 if(n > 0){
9 if (PGROUNDUP(sz + n) >= PLIC)
10 return -1;
11 if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
12 return -1;
13 }
14 // 添加复制函数
15 uvmkptcopy(p->pagetable, p->kernel_pagetable, sz-n, sz);
16 } else if(n < 0){
17 sz = uvmdealloc(p->pagetable, sz, sz + n);
18 }
19 p->sz = sz;
20 return 0;
21}
- userinit()
1// Set up first user process.
2void
3userinit(void)
4{
5 struct proc *p;
6
7 p = allocproc();
8 initproc = p;
9
10 // allocate one user page and copy init's instructions
11 // and data into it.
12 uvminit(p->pagetable, initcode, sizeof(initcode));
13 p->sz = PGSIZE;
14 uvmkptcopy(p->pagetable, p->kernel_pagetable, 0, p->sz);
15
16 // prepare for the very first "return" from kernel to user.
17 p->trapframe->epc = 0; // user program counter
18 p->trapframe->sp = PGSIZE; // user stack pointer
19
20 safestrcpy(p->name, "initcode", sizeof(p->name));
21 p->cwd = namei("/");
22
23 p->state = RUNNABLE;
24
25 release(&p->lock);
26}
总结
这个实验妈的真难,part2基本不是人能想得到的,虽然基本的思路是有……
这里必须认识到所谓虚拟内存其实是假的,最开始只有freelist上可以被使用的内存,内核也得自己构建一块块内存,从0x0到0x88000000(PHYSTOP)都需要被映射,只不过0x0到0x80000000(KERNELBASE)是被映射到实际的物理设备的(可以先这样子想),后面的0x80000000到end都是被映射到数据和代码,end到PHYSTOP才是真正可以被内核和进程使用的内存,且是以页为单位被使用:
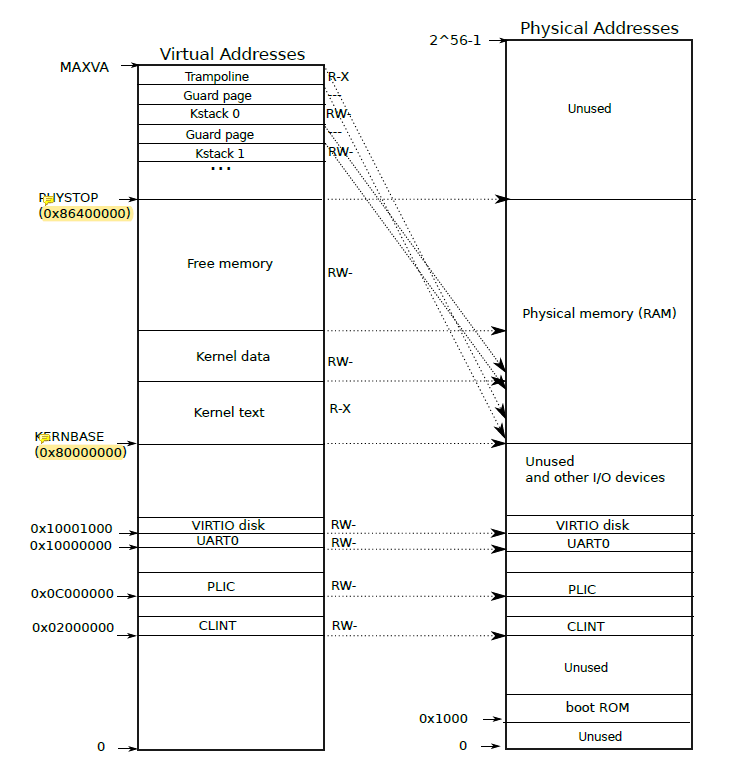
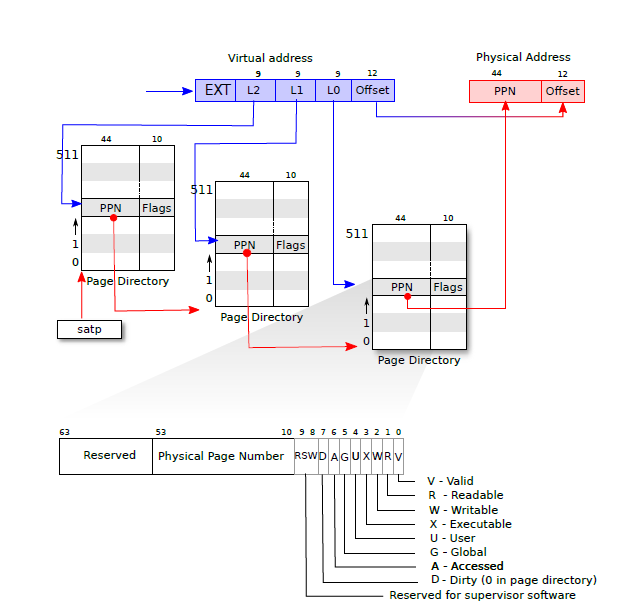
在全局kernel pagetable被初始化的时候trampoline和kstack都映射到free memory里面(书上图也画错了)。因此可以知道真正的程序都是运行在一块一块的页内存中的,外部通过pagetable/kernel pagetable将其组织起来,于是就有了一大块从零开始的、连续的虚拟内存的假象。下面这个图PHYSTOP错的,是0x88000000 但在这一过程中,除了程序所必须的物理内存,实际上pagetable也是被存储在内存中的(walk函数),只不过这个内存并不被程序实际使用,而是用来存储映射关系(第二级和第三级页表都是如此)。
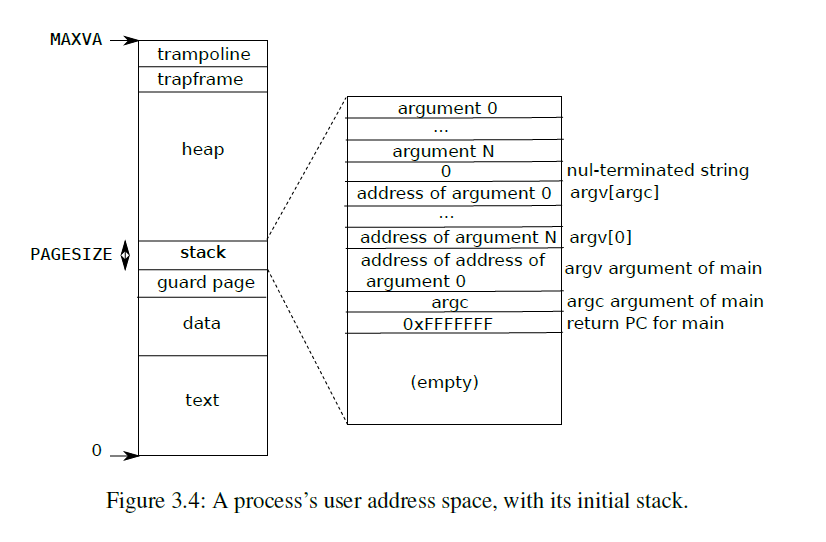
其实这其中最为关键的地方是在exec函数里,加载elf文件,并用新程序覆盖原来的旧程序,最后应该还调整了PC让新程序被执行,妙啊。
Lab4
前置知识
- .ld文件实际上是编译阶段要使用的,在这里会定义程序的代码段、数据段等需要存放的位置,并将一定的符号给暴露出去,例如_trampoline
- _entry文件是设置了很多块栈(RISC-V的栈是从上往下增长的),针对每一块CPU都设置了一页的栈,这个CPU栈的主要作用是处理内核模式下的中断和异常,这些堆栈是由start.c中初始化来的,与CPU数量一致。与kstack不同,kstack(内核栈)是用于处理进程在内核模式下的函数调用、中断和异常(即trap),数量与进程数量保持一致。因为在处理这些东西的时候仍然可能被中断,除了保存寄存器以外,也需要栈来保存函数调用的数据
- caller寄存器和callee寄存器:caller寄存器一般用于保存返回地址的,用于恢复原有的调用者的正常运行;callee寄存器一般用于保存函数返回值,用于给调用者使用(如果返回值过大那有可能保存的是地址)
RISC-V assembly
- Which registers contain arguments to functions? For example, which register holds 13 in main’s call to printf?
这里主要理解两张图:
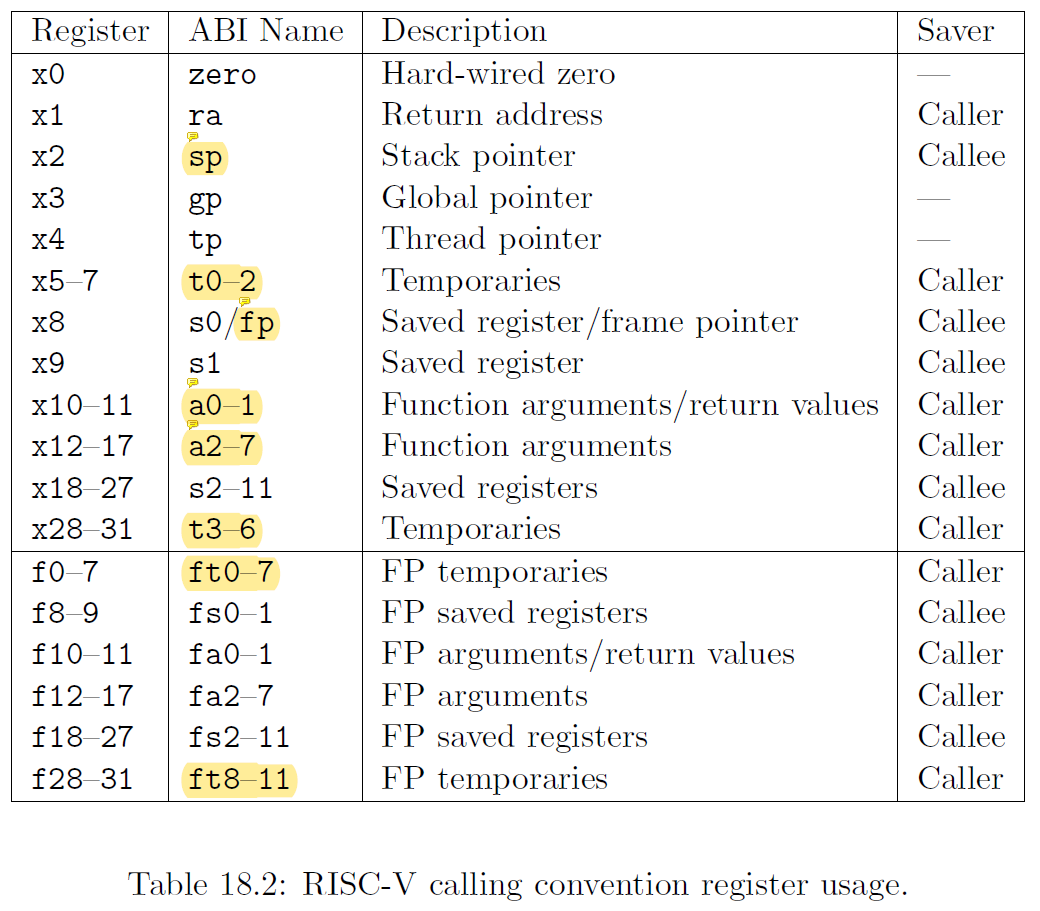
在代码中printf函数将控制序列放到a0中,将a1,a2分别存放两个参数,这与上表18.2基本一致,另外还需要了解一点栈帧的基本知识:RISC-V栈从上至下增长,且为小端(意味着返回的地址是最低有效位的地址),fp是该栈帧的基地址,sp的栈的栈顶地址,fp到sp之间即为一个栈帧,栈帧内首先存放返回地址,再一个就是上一个fp,用于找到上一个栈帧的位置(最终目的还是定位上一个栈帧的return address),再下来就是保存一些寄存器的值用作参数,最后为保存局部变量。
于是可以回答上述问题:1. a0 a1 a2, a2 contains 13
- Where is the call to function f in the assembly code for main? Where is the call to g? (Hint: the compiler may inline functions.)
这里倒没什么好讲的,主要是函数调用被编译器直接优化了。
因此:2. Acctually compiler inline it and pre-calculate it out
- At what address is the function printf located?
在汇编代码里也有提示:
130: 00000097 auipc ra,0x0 #此时ra内存的就是pc=0x30
234: 600080e7 jalr 1536(ra) # 630
其中0x630就是printf函数的地址,将立即数1536与ra内的值相加即得到了跳转的目标地址,在此之前ra内的地址就是pc的地址,而pc地址是0x30,加上1536则得出目标地址为1584(0x630)。
因此:3. 630
- What value is in the register ra just after the jalr to printf in main?
jalr是跳转指令,以上面第二行为例,首先将ra内容加上1536作为目标跳转地址,随后jalr会将ra的值设置为当前PC+4,用于返回函数后恢复正常运行。
因此:4. the address of current instruction plus 4
- …
Run the following code.
1unsigned int i = 0x00646c72;
2printf("H%x Wo%s", 57616, &i);
What is the output? Here’s an ASCII table that maps bytes to characters.The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set i to in order to yield the same output? Would you need to change 57616 to a different value?
57616的16进制为0xE110,%s则代表要读取的是字符串,因此默认小端读取,在ASCII码表中,0x72代表r,0x6c代表l,0x64代表d。因此可以得到最终输出。如果是大端的话则需要改变为0x726c640000000000,因为是64位的且要保证最后一位为停止符。57616我认为不需要变化,因为只要是正确读取正确输出那就没有问题。
因此:5. HE110 World 0x726c640000000000 no, i don’t need to
- …
In the following code, what is going to be printed after ‘y=’? (note: the answer is not a specific value.) Why does this happen?
1printf("x=%d y=%d", 3);
因此:6. a random number in register a2
Backtrace
Backtrace要求实现一个函数来打印从顶至下打印栈帧,还算比较简单,知道kstack是做什么用的(上面有),kstack是从上至下增长,stack frame长什么样(上面有)即可。
- 首先在kernel/printf.c中定义函数backtrace:
1void backtrace(void)
2{
3}
- 在kernel/defs.h中增加函数声明
- kernel/riscv.h中增加以下函数用于读取寄存器fp(frame pointer),C语言里写汇编,够骚
1static inline uint64
2r_fp()
3{
4 uint64 x;
5 asm volatile("mv %0, s0"
6 : "=r"(x));
7 return x;
8}
- 完善backtrace定义
1void backtrace(void)
2{
3 // current fp, fp contains the top fp address
4 uint64 fp = r_fp();
5 while(fp != PGROUNDUP(fp))
6 {
7 printf("%p\n",*((uint64*)(fp - 8)));
8 fp = *((uint64 *)(fp - 16));
9 }
10}
- bbtest一下可以正常输出结果
1$ bttest
20x0000000080002ccc
30x0000000080002ba6
40x0000000080002890
并可以使用addr2line来根据地址逆向查找对应源文件位置
1❯ addr2line -e kernel/kernel 0x0000000080002ccc 0x0000000080002ba6 0x0000000080002890
2/home/zhangzihao/xv6-labs-2020/kernel/sysproc.c:62
3/home/zhangzihao/xv6-labs-2020/kernel/syscall.c:140
4/home/zhangzihao/xv6-labs-2020/kernel/trap.c:76
这里补充一下: addr2line是一个用于逆向查找程序地址对应源代码位置的工具。它是GNU binutils工具集的一部分,可用于解析程序的地址并将其映射到源代码的行号和文件名。它常用于调试和错误排查过程中,特别是在崩溃和错误报告的分析中。通过使用addr2line,可以将程序计数器(Program Counter,PC)或地址作为输入,然后获取与该地址相关联的源代码位置信息。
- 将backtrace加到panic函数里!
- 小结
这个实验很简单,fp最后会回到进程对应的kstack的底部(也是地址最高点因此要PGROUNDUP),%p是带0x的地址打印,fp是栈帧的底部,但是从栈帧读取数据还是正常升序读取,因此要使用fp-8找到return address的位置,fp-16则是要找到上一个栈帧的地址。
这里唯一需要注意的是地址与数字的加减,要记住地址的运算出来的永远是地址单元的数量,这个地址单元是根据类型而定的,而非一个字节!
Alarm
实验要求很简单,完成两个系统调用,组合之下能够完成类似单片机设置定时中断的功能,实现思路很简单,跟着hint做就行,比page table简单1w倍。
- 在Makefile中增加alarmtest.c
1UPROGS=\
2...
3 $U/_alarmtest\
- user/user.h中增加两个新的系统调用
1int sigalarm(int ticks, void (*handler)());
2int sigreturn(void);
- user/usys.pl中增加系统调用对应的entry
1entry("sigalarm");
2entry("sigreturn");
- 随便挑一个内核文件增加对应的系统调用,sigalarm负责获取参数并将其记录于proc结构体里,此时sigreturn只用return 0即可,此外记得在proc.h中增加proc结构体中的字段ticks和handler
1uint64
2sys_sigalarm(void)
3{
4 struct proc* p = myproc();
5 // get interval and handler, store it to proc struct
6 argint(0, &p->ticks);
7 argaddr(1, &p->handler);
8 return 0;
9}
10uint64
11sys_sigreturn(void)
12{
13 return 0;
14}
- 在syscall.c中增加对应的外部引用和标号,在此不再赘述
- trap.c/usertrap中增加如下语句,从而保证能够在系统时钟中断trap返回时直接去handler函数执行
1if(which_dev == 2)
2{
3 // the alarm is set
4 if (p->ticks != 0)
5 {
6 p->ticks_to_last++;
7 if (p->ticks_to_last == p->ticks)
8 {
9 // let user app invoke handler
10 p->trapframe->epc = p->handler;
11 }
12 }
13 yield();
14}
至此基本完成了test0。 7. test1和2主要的目的是恢复时钟中断trap返回时的状态,首先需要在中断trap时保存对应状态,这里我偷懒直接用trapframe结构体保存了一下
1---
2kernel/proc.h中proc中增加的字段
3int ticks;
4int ticks_to_last;
5uint64 handler;
6struct trapframe trapframe_for_sig;
7---
8kernel/trap.c中usertrap中的函数
9// give up the CPU if this is a timer interrupt.
10if(which_dev == 2)
11{
12 // the alarm is set
13 if (p->ticks != 0)
14 {
15 p->ticks_to_last++;
16 if (p->ticks_to_last == p->ticks)
17 {
18 // store the state
19 p->trapframe_for_sig = *p->trapframe;
20
21 // let user app invoke handler
22 p->trapframe->epc = p->handler;
23 }
24 }
25 yield();
26}
- 另外还需要在sigreturn中恢复状态
1uint64
2sys_sigreturn(void)
3{
4 struct proc* p = myproc();
5 *p->trapframe = p->trapframe_for_sig;
6// 这里不用+4的原因是该次trap是时钟中断trap,而非syscall
7// p->trapframe->epc += 4;
8 p->ticks_to_last = 0;
9 return 0;
10}
- 小结:
- 设定定时函数时的流程为
- syscall
- (syscall)trap
- 定时函数被调用的流程为
- 定时器中断
- (定时器)trap
- usertrap中判断是否达到了设定时间,保存当前trapframe并通过修改trapframe中的epc来设置trap返回后的跳转
- trap返回根据设定的epc设置pc,从而实现跳转效果
- 定时函数返回流程为
- 定时器函数内执行sigreturn系统调用
- trap
- sigreturn内恢复现场并恢复trapframe!
- 设定定时函数时的流程为
这个实验很简单,但很好的展示了如何设定定时函数,最后的返回更是精妙,代码量不多,但能够很好地完成任务,good!
Lab5
前置知识
这个实验要做的是完成lazy allocation,还是虚拟内存相关的实验,copy-on-write,paging from disk也是一样。做这个实验之前还是要知道PTE的一些flag所代表的含义
Eliminate allocation from sbrk()
只是lazy allocation的前置,比较简单,课上也有演示,只需要在sbrk分配内存时不真正分配,只是记录需要增加的大小
1uint64
2sys_sbrk(void)
3{
4...
5 myproc()->sz = myproc()->sz + n;
6// if(growproc(n) < 0)
7// return -1;
8 return addr;
9}
最终按照测试打印如下:
1$ echo hi
2usertrap(): unexpected scause 0x000000000000000f pid=3
3 sepc=0x00000000000012ac stval=0x0000000000004008
4panic: uvmunmap: not mapped
可以简单分析一下:
usertrap的报错是unexpected scause 0xf,实际上是因为用户程序中的指令访问了不能访问的内存,在usertrap中没有对应处理的程序,pid=3是因为第一个process是init,第二个是shell,第三个就是echo hi了(先fork再exec),sepc记录的是出错前的用户pc指令,stval是出错时的虚拟地址
panic则是因为发生错误后需要清理内存,但是此时根据sz清理的内存实际上没有被map,因此会出错。
Lazy allocation和Lazytests and Usertests
这两部分情况比较特殊,可以一起做了
首先仔细分析一下,如果sbrk时不分配内存,只是记录sz的大小,此时如果进程访问未被分配的内存就会发生page fault,由trap过程中的usertrap进行处理,按照题目hints可以知道此时scause是13或15,此时需要对错误进行处理:
- 获取发生错误时的虚拟地址
- 申请物理内存
- 将虚拟地址和物理内存映射起来
具体为usertrap函数中:
1else if (r_scause() == 13 || r_scause() == 15){
2 // page fault handler
3 uint64 va = r_stval();
4 if (va > myproc()->sz || va < PGROUNDDOWN(myproc()->trapframe->sp)){
5 p->killed = 1;
6 } else {
7 char* pa = kalloc();
8 if (pa == 0) {
9 p->killed = 1;
10 } else {
11 memset(pa, 0, PGSIZE);
12 va = PGROUNDDOWN(va);
13 if(mappages(myproc()->pagetable, va, PGSIZE, (uint64)pa, PTE_W|PTE_X|PTE_R|PTE_U) != 0){
14 kfree(pa);
15 p->killed=1;
16 exit(-1);
17 }
18 }
19 }
20}
这里需要注意的是第四行如果内存读取到了超出最大地址和用户虚拟地址以下时是真的发生了page fault,此时需要杀掉进程,并且要处理申请不到内存和map出错的情况。
此外在sys_sbrk函数中还需要对增加后的地址大于MAXVA或者小于0时进行处理,并且除了lazy allocation之外,在减少内存时需要立刻减少,这里直接参照growproc来写就OK
1uint64
2sys_sbrk(void)
3{
4 int addr;
5 int n;
6
7 if(argint(0, &n) < 0)
8 return -1;
9 addr = myproc()->sz;
10 if (myproc()->sz + n >= MAXVA || myproc()->sz + n <= 0)
11 {
12 return addr;
13 }
14 myproc()->sz = myproc()->sz + n;
15
16 if (n < 0){
17 uvmdealloc(myproc()->pagetable, addr, myproc()->sz);
18 }
19
20 return addr;
21}
除了上述的正常trap情况,如果在内核态时使用copyin和copyout函数,也同样需要进行类似usertrap的处理,因为此时不会有usertrap来正常处理page fault的情况,主要还是修改walkaddr函数,删除原有pte为0和valid flag为0的情况,增加如下处理
1if (pte == 0 || (*pte & PTE_V) == 0) {
2 struct proc *p = myproc();
3 if(va >= p->sz || va < PGROUNDDOWN(p->trapframe->sp)) return 0;
4
5 pa = (uint64)kalloc();
6 if (pa == 0) return 0;
7
8 if (mappages(p->pagetable, va, PGSIZE, pa, PTE_W|PTE_R|PTE_U|PTE_X) != 0) {
9 kfree((void*)pa);
10 return 0;
11 }
12 return pa;
13}
最后,取消掉panic的地方即可(uvmcopy和uvmunmap)
这个实验还有一个值得注意的地方是sh、fork和exec指令,其实sbrk是由sh中的malloc调用来执行的,目前还不是很了解这三者作用的细节,不过CSAPP好像有个shell实验可以试试看。
Lab6
其实这个实验应该和Lab5的lazy allocation一起做了的,效率应该是比较高的
问题引入
fork时会将内存复制一遍到新的进程地址空间,但实际上有时候fork后面马上跟了一个exec,这就导致之前的复制完全是没有意义的,另一方面,其实需要更改的可能只有一小部分数据,那按理来说只需要保证其他数据在真实的物理内存中只有一份,而需要更改数据存在两份(父子进程各自持有),在该种情况下,只需要更改映射就OK了
所以COW fork需要完成的主要功能就是延迟分配和复制物理内存直到真的需要,主要任务有以下几个:
- 为子进程创建pagetable,但这个pagetable的所有pte都指向父进程的实际物理内存,即存在相同的映射
- 将父子进程的所有PTE的flag都标记为不可写,当任何一个进程试图写的时候则会触发page fault,此时由trap来处理page faul:分配物理内存,复制新页面,更新该进程的PTE
根据提示有以下几步:
- 更改uvmcopy在子进程的地址空间映射父进程的物理内存,并清除PTE的可写标志位
- 更改usertrap来识别page fault(类似lazy allocation),分配新的物理内存,并从共享内存中copy对应数据,将其安装到page table中,更改PTE的可写标志位
- 保证物理内存在没有映射后会被正确地释放,例如通过引用计数来统计引用每个物理页面的数量,kalloc分配时设置为1,fork存在共享时增加引用计数,进程从其页表中删除页面时减少引用技术。只有引用计数为0时才能够kfree掉。可以通过一个数组来追踪每个页面引用计数的数量,通过页面的物理地址/4096来索引空闲列表中的每一个物理页面(所以有多少页面呢?)
- 更改copyout来处理COW导致的page fault
- 如果COW page fault发生后没有空闲内存了,则直接杀掉进程(尝试写数据的进程),引用计数减1
Copy on Write
- fork步骤中,最重要的是步骤是从父进程赋值进程到子进程,其中最为重要的是uvmcopy函数,这一步需要更改的如下:
1int
2uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
3{
4 pte_t *pte;
5 uint64 pa, i;
6 uint flags;
7 // char *mem;
8
9 for(i = 0; i < sz; i += PGSIZE){
10 if((pte = walk(old, i, 0)) == 0)
11 panic("uvmcopy: pte should exist");
12 if((*pte & PTE_V) == 0)
13 panic("uvmcopy: page not present");
14 pa = PTE2PA(*pte);
15 // record at RSW to tell whether a PTE is COW mapping
16 // modify old pagetable's pte to clear PET_W in parent and child
17 *pte &= ~PTE_W;
18 *pte |= PTE_COW;
19 flags = PTE_FLAGS(*pte);
20
21 // in cow fork, we don't allocate memory for copying
22 if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
23 // and don't free any memory
24 goto err;
25 }
26 // increase the reference count
27 acquire(&(mem_ref[pa/PGSIZE].lock));
28 mem_ref[(uint64)pa/PGSIZE].cnt++;
29 release(&(mem_ref[pa/PGSIZE].lock));
30 }
31 return 0;
32
33 err:
34 uvmunmap(new, 0, i / PGSIZE, 1);
35 return -1;
36}
简单总结就是先不要分配内存,保证父进程和子进程来映射同一片物理内存,并且在两者中都将pte的权限改为只读,并且用一个标志位(PTE_COW宏和PTE_V宏类似)来表示该页内存为COW内存(方便后续处理)
- COW会导致进程或内核在访问COW内存页的时候发生page fault错误,在usertrap中需要识别该错误,并对其进行处理:
1void
2usertrap(void)
3{
4...
5 else if (r_scause() == 15 || r_scause() == 13) {
6 // cow page fault handler
7 uint64 va = r_stval();
8 if (cow_copy(p->pagetable, va) == 0)
9 {
10 p->killed = 1;
11 }
12 // va = PGROUNDDOWN(va);
13 // uint64 pa = walkaddr(p->pagetable, va);
14 // pte_t *pte = walk(p->pagetable, va, 0);
15 //
16 // if (get_mem_ref(pa) == 1)
17 // {
18 // // 如果某个进程访问页面,此时还是发生缺页中断,则只需要更改标志位即可
19 // // 此时意味着没有进程与其共享
20 // *pte &= (~PTE_COW);
21 // *pte |= (PTE_W);
22 // } else {
23 // // allocate new memory
24 // char* npa = kalloc();
25 // // *pte = (*pte) & (~PTE_V);
26 // uint flags = (PTE_FLAGS(*pte) | PTE_W) & (~PTE_COW);
27 //
28 // if (npa == 0 || pa == 0)
29 // {
30 // p->killed = 1;
31 // }
32 // // defer allocating and copying at here
33 // memmove(npa, (char *)pa, PGSIZE);
34 // // unmap the old page
35 // uvmunmap(p->pagetable, PGROUNDDOWN(va), 1, 1);
36 // if (mappages(p->pagetable, va, PGSIZE, (uint64)npa, flags) != 0){
37 // kfree(npa);
38 // p->killed = 1;
39 // }
40 // // decrease the count
41 // kfree((char*)PGROUNDDOWN(pa));
42 // }
43 }
44...
45}
注释的是自己手撸的版本,可惜在赋值标志位的时候人赋值晕了,后面感觉既然在copyout要用那的确应该搞个函数来封装一下,但有点懒就偷了一个老哥的,不过换汤不换药。主要思想就是如果是只有一个引用计数的内存页,那就恢复写权限并取消COW标志位,否则就分配新内存,并取消原有映射,建立新映射,同时减少内存页的引用计数
- 在内核中也可能访问物理内存,此时也需要在copyout中处理
1int
2copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
3{
4 ...
5 if (cow_check(pagetable, va0) != 0)
6 {
7 // pa0 must be returned
8 pa0 = cow_copy(pagetable, va0);
9 }
10 if(pa0 == 0)
11 return -1;
12 ...
13}
- 引用计数,通过构造自旋锁,给每个可分配的内存页都在操作系统中搞了个锁,这个步骤还是比较繁琐的(参考别人的,有一定修改)
- 首先是定义锁
1struct mem_ref
2{
3 struct spinlock lock;
4 int cnt;
5};
6
7struct mem_ref mem_ref[PHYSTOP/PGSIZE];
- 随后写一个辅助函数,在线程安全的情况下获取锁
1int
2get_mem_ref(uint64 pa)
3{
4 acquire(&(mem_ref[pa/PGSIZE].lock));
5 int res = mem_ref[(uint64)pa/PGSIZE].cnt;
6 release(&(mem_ref[pa/PGSIZE].lock));
7 return res;
8}
- 在kinit中初始化锁
1void
2kinit()
3{
4 for(int i = 0; i < PHYSTOP/PGSIZE; ++i)
5 {
6 // initialize the lock
7 initlock(&(mem_ref[i].lock), "kmem_ref");
8 }
9 initlock(&kmem.lock, "kmem");
10 freerange(end, (void*)PHYSTOP);
11}
- 在freerange中对引用计数进行赋值
1void
2freerange(void *pa_start, void *pa_end)
3{
4 char *p;
5 p = (char*)PGROUNDUP((uint64)pa_start);
6 for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
7 {
8 // initialize the count
9 mem_ref[(uint64)p/PGSIZE].cnt = 1;
10 kfree(p);
11 }
12}
- 当且仅当引用计数为0时才可以在kfree中释放内存
1void
2kfree(void *pa)
3{
4 ...
5 // only free pa when memory reference is 0
6 uint64 pa_idx = (uint64)pa / PGSIZE;
7 acquire(&(mem_ref[pa_idx].lock));
8
9 mem_ref[pa_idx].cnt--;
10 if (mem_ref[pa_idx].cnt > 0)
11 {
12 release(&(mem_ref[pa_idx].lock));
13 return;
14 }
15 release(&(mem_ref[pa_idx].lock));
16 ...
17}
- 在分配内存页的时候需要给引用计数赋值为1(因为此时分配的内存之前被使用过后现在值为0,不符合实际意义)
1void *
2kalloc(void)
3{
4 ...
5 if(r)
6 {
7 uint64 pa_idx = (uint64)r / PGSIZE;
8 acquire(&(mem_ref[pa_idx].lock));
9 mem_ref[pa_idx].cnt = 1;
10 release(&(mem_ref[pa_idx].lock));
11
12 kmem.freelist = r->next;
13 }
14 ...
15}
- 将cow的处理过程写成一个函数,思路就是分配、取消映射再映射,偷懒偷了别人的函数了
1uint64
2cow_copy(pagetable_t pagetable, uint64 va)
3{
4
5 va = PGROUNDDOWN(va);
6 pte_t *pte = walk(pagetable, va, 0);
7 uint64 pa = PTE2PA(*pte);
8
9 if(get_mem_ref(pa) == 1)
10 {
11 *pte = (*pte) & (~PTE_COW);
12 *pte = (*pte) | (PTE_W);
13 return pa;
14 }
15 else
16 {
17 char *mem = kalloc();
18 if(mem == 0){
19 return 0;
20 }
21
22 memmove(mem, (char *)pa, PGSIZE);
23 *pte = (*pte) & (~PTE_V);
24 uint64 flag = PTE_FLAGS(*pte);
25 flag = flag | PTE_W;
26 flag = flag & (~PTE_COW);
27
28 if(mappages(pagetable, va, PGSIZE, (uint64)mem, flag) != 0)
29 {
30 kfree(mem);
31 return 0;
32 }
33 // decrease it!
34 kfree((char*)PGROUNDDOWN(pa));
35
36 return (uint64)mem;
37 }
38}
- 另外一个辅助的函数本质上很简单,但由于复制的时候手贱把一些失败处理的删了导致测试通不过,抓耳挠腮半天才搞好,还得是测试啊妈的
1int
2cow_check(pagetable_t pagetable, uint64 va)
3{
4 if(va > MAXVA)
5 return 0;
6
7 pte_t *pte = walk(pagetable, va, 0);
8 if(pte == 0)
9 {
10 printf("fuck");// 这个是发现usertests会测试pte为0的边界情况,妈的!
11 return 0;
12 }
13 if(((*pte) & (PTE_V)) == 0)
14 return 0;
15 int res = (*pte) & (PTE_COW);
16 return res;
17}
总结:
- 重复两次的逻辑尽量给他函数封装
- 一个函数太长了也要切割(其实最好是在写之前切割)
- 异常处理是非常必要的,在比较边界的情况下会导致出错,虽然可能功能基本实现了,但不够鲁棒!
- gdb的调试不仅需要对程序足够了解,还得好好学工具的使用啊,gdb能帮很大的忙
- COW的逻辑不难,主要难的是对边界情况的处理,这个实验其实最好和lazy allocation一起做
- 还是得研究一下测试程序,如何验证程序没有错误也是非常重要的
- 虽然自己写了一点,但代码能跑要感谢这个老哥
Lab7
Uthread
该实验目的就是添加一个用户级的thread(不支持真正的并发),栈和寄存器由thread自己保存,感觉更像协程,看懂xv6实现底层的话还是比较简单的:
- 从内核中扒一下context结构体,塞thread结构体里,很类似proc结构体的操作:
1struct context {
2 uint64 ra;
3 uint64 sp;
4
5 // callee-saved
6 uint64 s0;
7 uint64 s1;
8 uint64 s2;
9 uint64 s3;
10 uint64 s4;
11 uint64 s5;
12 uint64 s6;
13 uint64 s7;
14 uint64 s8;
15 uint64 s9;
16 uint64 s10;
17 uint64 s11;
18};
19
20struct thread {
21 char stack[STACK_SIZE]; /* the thread's stack */
22 int state; /* FREE, RUNNING, RUNNABLE */
23 struct context context;
24};
- 那么创建线程应该做些什么呢?让该线程有正确的上下文,如果该线程要被执行了,让程序能够正确的执行,在此就是指定正确的sp寄存器和ra寄存器内容
1void
2thread_create(void (*func)())
3{
4 struct thread *t;
5
6 for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
7 if (t->state == FREE) break;
8 }
9 // 找到了空闲线程后赋值为RUNNABLE
10 t->state = RUNNABLE;
11 // YOUR CODE HERE
12 // 在sp寄存器中存储正确的栈指针位置(栈顶到栈底)
13 t->context.sp = (uint64)t->stack + STACK_SIZE - 1;
14 t->context.ra = (uint64)func;
15}
- thread_switch.S,这个没啥好说的,直接扒内核代码
1thread_switch:
2 sd ra, 0(a0)
3 sd sp, 8(a0)
4 sd s0, 16(a0)
5 sd s1, 24(a0)
6 sd s2, 32(a0)
7 sd s3, 40(a0)
8 sd s4, 48(a0)
9 sd s5, 56(a0)
10 sd s6, 64(a0)
11 sd s7, 72(a0)
12 sd s8, 80(a0)
13 sd s9, 88(a0)
14 sd s10, 96(a0)
15 sd s11, 104(a0)
16
17 ld ra, 0(a1)
18 ld sp, 8(a1)
19 ld s0, 16(a1)
20 ld s1, 24(a1)
21 ld s2, 32(a1)
22 ld s3, 40(a1)
23 ld s4, 48(a1)
24 ld s5, 56(a1)
25 ld s6, 64(a1)
26 ld s7, 72(a1)
27 ld s8, 80(a1)
28 ld s9, 88(a1)
29 ld s10, 96(a1)
30 ld s11, 104(a1)
31 ret /* return to ra */
- thread_schedule,这个也没啥好说的,直接加上3中的函数即可(位置都指定了)
1thread_switch((uint64)&t->context, (uint64)¤t_thread->context);
小结:主要是理解概念,这个实验设计得很好,准确理解了xv6如何完成切换的话只需要少量的代码即可完成功能,非常不错的实验!
Using threads
解决的核心问题:两个线程同时访问资源,应该如何保证线程安全?如果线程安全做到了,又如何保证性能?
- 保证线程安全 朴素的思想就是加锁,pthread库提供了互斥锁,使用方式如下:
1pthread_mutex_t lock; // declare a lock
2pthread_mutex_init(&lock, NULL); // initialize the lock
3pthread_mutex_lock(&lock); // acquire lock
4pthread_mutex_unlock(&lock); // release lock
只需要在get和put函数加锁即可解决:
1pthread_mutex_t lock;
2
3static struct entry *
4get(int key)
5{
6 // hash操作,拼接靠链表
7 int i = key % NBUCKET;
8
9 struct entry *e = 0;
10
11 pthread_mutex_lock(&lock);
12 for (e = table[i]; e != 0; e = e->next)
13 {
14 if (e->key == key)
15 break;
16 }
17 pthread_mutex_unlock(&lock);
18
19 return e;
20}
21
22static void put(int key, int value)
23{
24 int i = key % NBUCKET;
25 // is the key already present?
26 struct entry *e = 0;
27 pthread_mutex_lock(&lock);
28 for (e = table[i]; e != 0; e = e->next)
29 {
30 if (e->key == key)
31 break;
32 }
33 if (e)
34 {
35 // update the existing key.
36 e->value = value;
37 }
38 else
39 {
40 // the new is new.
41 insert(key, value, &table[i], table[i]);
42 }
43 pthread_mutex_unlock(&lock);
44}
要记得完成锁的初始化,但以上的大锁又会带来新的问题,即难以使用CPU的性能,现在几乎是同步执行了,没有什么意义,因此引入了以下问题。
- 如何在保证线程安全的情况下榨干CPU多核性能 这里很自然的思想是提供细粒度的锁,例如初始化多个锁,根据访问的key放到合适的位置,或者,对每一个节点都加单独的锁(很麻烦懒得做了hhh)。于是可以根据NBUCKET的数量(理解一下哈希表)来上锁:
1pthread_mutex_t lock[NBUCKET];
2
3static struct entry *
4get(int key)
5{
6 // hash操作,拼接靠链表
7 int i = key % NBUCKET;
8
9 struct entry *e = 0;
10
11 pthread_mutex_lock(&lock[i]);
12 for (e = table[i]; e != 0; e = e->next)
13 {
14 if (e->key == key)
15 break;
16 }
17 pthread_mutex_unlock(&lock[i]);
18
19 return e;
20}
21
22static void put(int key, int value)
23{
24 int i = key % NBUCKET;
25 // is the key already present?
26 struct entry *e = 0;
27 // 根据i值决定哪把锁
28 pthread_mutex_lock(&lock[i]);
29 for (e = table[i]; e != 0; e = e->next)
30 {
31 if (e->key == key)
32 break;
33 }
34 if (e)
35 {
36 // update the existing key.
37 e->value = value;
38 }
39 else
40 {
41 // the new is new.
42 insert(key, value, &table[i], table[i]);
43 }
44 pthread_mutex_unlock(&lock[i]);
45}
46
47int main(int argc, char *argv[])
48{
49 ...
50 // 互斥锁初始化
51 for (int i = 0; i < NBUCKET; i++)
52 {
53 pthread_mutex_init(&lock[i], NULL);
54 }
55 ...
56}
其实上面的实现还有些问题,如果线程只是读的话,没必要加锁,让其读好了,因此可以把get中的锁删了,性能可以再一次提升:
- 互斥锁是什么,和自旋锁睡眠锁有什么不同,条件变量和信号量又是什么?
参考这个
- pthread提供了哪些接口,含义又是什么?
TODO
Barrier
介绍了条件变量相关知识,利用pthread提供的条件变量机制,让所有线程都能执行完一轮后再进入下一次循环,理解条件变量即可,很类似sleep锁
1static void
2barrier()
3{
4 // YOUR CODE HERE
5 //
6 // Block until all threads have called barrier() and
7 // then increment bstate.round.
8 //
9 pthread_mutex_lock(&bstate.barrier_mutex);
10 // 记录有多少个线程到达此处
11 bstate.nthread++;
12 // 一旦线程到达数量等于总数量,则进入下一轮
13 // 否则睡眠并等待
14 if (bstate.nthread == nthread)
15 {
16 bstate.nthread = 0;
17 bstate.round++;
18 pthread_cond_broadcast(&bstate.barrier_cond);
19 }
20 else
21 {
22 // 释放锁
23 pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
24 }
25 pthread_mutex_unlock(&bstate.barrier_mutex);
26}
核心思想是计算到达的线程有多少个,早到的就等一等,最后一个到的来完成唤醒其他线程的任务 小结:其实第一个实验还好,后面俩实验完全是pthread教程了,不写感觉也问题不大。
Lab8
Memory allocator
问题来源于在分配或释放内存时,内核总是一把大锁保平安,实际上这样在多核情况下的性能并不好,那么一个有趣的思路是既然CPU们争抢一把锁,不如给每个CPU一份free list用于管理内存,同时给每个free list一把锁,来减少资源竞争,同时要完成的任务是当一个CPU的free list没空闲内存之后,要去其他CPU那里偷点过来。 那这里就会有两个基本的思路:
- 在初始化的时候计算空闲内存页的数量以及CPU数量,均分一下好了(后面发现其实这种想法还是得依赖于偷)
- 只给第一个CPU,让其他CPU要内存的时候自己去偷
这里用第二种思路好了,正好可以妙用一手偷男机制
基本的想法是在freepage(其实是kfree)的时候获取cpu id,把所有内存都给这个运行freepage的cpu(记得关中断),这时候基本的问题就来了,需要初始化一个和CPU数量相同的数组,并且需要初始化这些lock:
1struct {
2 struct spinlock lock;
3 struct run *freelist;
4} kmem[NCPU]; // 根据cpu数量初始化数组
5
6void
7kinit()
8{
9 // for 初始化所有cpu内存锁
10 for (int i = 0; i < NCPU; i++) {
11 // 这里第二个就算了,懒得改了
12 initlock(&kmem[i].lock, "kmem");
13 }
14 // initlock(&kmem.lock, "kmem");
15 freerange(end, (void*)PHYSTOP);
16}
17
18void
19kfree(void *pa)
20{
21 struct run *r;
22
23 if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
24 panic("kfree");
25
26 // Fill with junk to catch dangling refs.
27 memset(pa, 1, PGSIZE);
28
29 r = (struct run*)pa;
30
31 push_off();
32 // 获取cpuid
33 int id = cpuid();
34 // 根据cpuid获取锁
35 // 感觉没有必要获取锁了这里,又没有并发问题
36 // 妈的不对,仔细想想steal的时候会有并发问题。。
37 acquire(&kmem[id].lock);
38 r->next = kmem[id].freelist;
39 kmem[id].freelist = r;
40 release(&kmem[id].lock);
41 pop_off();
42}
43
44void *
45kalloc(void)
46{
47 struct run *r;
48 // 这里需要思考一下,kfree一定能snyx
49
50 push_off();
51 int id = cpuid();
52
53
54 acquire(&kmem[id].lock);
55 r = kmem[id].freelist;
56 if(r)
57 kmem[id].freelist = r->next;
58 else {
59 // 如果r已经空了就会很坏很坏
60 // 只能偷点
61 for(int i = 0; i < NCPU; i++) {
62 // 不要重复去搞
63 if(id == i) continue;
64 acquire(&kmem[i].lock);
65 if (kmem[i].freelist) {
66 // 如果别人的有货,就偷一片过来
67 r = kmem[i].freelist;
68 kmem[i].freelist = kmem[i].freelist->next;
69 release(&kmem[i].lock);
70 break;
71 }
72 release(&kmem[i].lock);
73 }
74 }
75 release(&kmem[id].lock);
76 pop_off();
77
78
79 if(r)
80 memset((char*)r, 5, PGSIZE); // fill with junk
81 return (void*)r;
82}
Buffer cache
在现代 OS 中,所有 I/O 操作都不会直接与 disk 打交道,一般都是将 disk 中的数据拷贝到 memory 中,进程再从 memory 中进行读写。memory 中用来暂存 disk 数据的地方,叫做 Buffer cache 多个进程同时使用文件系统时,会对一把大锁(bcache.lock)产生竞争,任务就是减少对这把锁的竞争,基本思路都是把锁改小,比如让每个小的缓存都有一个锁,要求修改bget和brelse来减少对bcache.lock的竞争 按照提示看来是要用hash表了,blockno来作为key,根据提示有以下几点需要注意:
- 可以用固定数量的hash表,只要能够映射就OK
- 在hash表内搜索或增加条目必须是原子的
- 之前用的双向链表的形式必须要删(看来得大改妈的),并且使用时间标记(ticks)来看看谁是最不常用的buffer,且引用计数为0,且没必要在brelse中获取bcache lock(这句没搞懂为什么)
这道题目要搞清楚每一个锁是用来保护哪些数据的,保持一致,锁保护的数据要不同
其实问题也是非常清晰的:bcache.lock这个锁太大了,为了减少竞争只能减少锁的大小,因此这里采用上一章的一个很有意思的主题,哈希表,每个哈希表又对应一条双向链表,来保存buffer。
- 修改bcache结构体,采用和上一章中相同的方式保存数据
1#define NBUCKET 13
2
3struct
4{
5 // struct spinlock lock; // 一把大锁保平安
6 struct buf buf[NBUF];
7 struct buf buckets[NBUCKET];
8 struct spinlock locks[NBUCKET];
9
10 // Linked list of all buffers, through prev/next.
11 // Sorted by how recently the buffer was used.
12 // head.next is most recent, head.prev is least.
13 // struct buf head;
14} bcache;
locks保护对应的buckets
- 修改binit来给锁进行初始化,并且把所有buf都挂载到buckets[0]上,让其他bucket来偷
1void binit(void)
2{
3 struct buf *b;
4
5 // initlock(&bcache.lock, "bcache");
6 for (int i = 0; i < NBUCKET; i++)
7 {
8 initlock(&bcache.locks[i], "bcache");
9 // 先自指之后可以偷男来偷一手
10 bcache.buckets[i].prev = &bcache.buckets[i];
11 bcache.buckets[i].next = &bcache.buckets[i];
12 }
13
14 for (b = bcache.buf; b < bcache.buf + NBUF; b++)
15 {
16 // 这里是借用了原有的方法,不过先都挂在第一个bucket上
17 // 之后偷一偷分配出去
18 b->next = bcache.buckets[0].next;
19 b->prev = &bcache.buckets[0];
20 initsleeplock(&b->lock, "buffer");
21 bcache.buckets[0].next->prev = b;
22 bcache.buckets[0].next = b;
23 }
24}
- 先改brelse,这个函数的作用是释放这个block buffer的使用权,并减少其引用计数,若引用计数为0记录一下使用时间,用trap中的ticks即可
1void brelse(struct buf *b)
2{
3 if (!holdingsleep(&b->lock))
4 panic("brelse");
5
6 releasesleep(&b->lock);
7
8 // 这里就hash了一手,取模也是hash
9 acquire(&bcache.locks[b->blockno % NBUCKET]);
10 b->refcnt--;
11 if (b->refcnt == 0)
12 {
13 b->time = ticks; // 这个time是在buf.h中加的
14 }
15 release(&bcache.locks[b->blockno % NBUCKET]);
16}
这里可以停一下想想为什么需要睡眠锁,如果多个进程都访问同一块block的buffer的话,他们的确可以找到这个buffer,但很有可能这个buffer被其他进程在用了,此时只能等待,但万万不能自旋,鬼知道别人要用多久,毕竟释放权在别人手上,只能先睡眠了。当别人使用完毕,那就调用brelse,来唤醒这些睡眠的进程,并且别人使用完了后把引用计数减1
- bpin和bunpin
这个思路就很简单,直接hash一手就ok
1void bpin(struct buf *b)
2{
3 acquire(&bcache.locks[b->blockno % NBUCKET]);
4 b->refcnt++;
5 release(&bcache.locks[b->blockno % NBUCKET]);
6}
7
8void bunpin(struct buf *b)
9{
10 acquire(&bcache.locks[b->blockno % NBUCKET]);
11 b->refcnt--;
12 release(&bcache.locks[b->blockno % NBUCKET]);
13}
- bget是最麻烦的,基本思路和上一道的kalloc是相同的,先自己找,不够就向别人那里偷
1static struct buf *
2bget(uint dev, uint blockno)
3{
4 struct buf *b;
5
6 int key = blockno % NBUCKET;
7
8 acquire(&bcache.locks[key]);
9 // 找找这个block是不是已经被缓存了
10 for (b = bcache.buckets[key].next; b != &bcache.buckets[key]; b = b->next)
11 {
12 if (b->dev == dev && b->blockno == blockno)
13 {
14 b->refcnt++;
15 release(&bcache.locks[key]);
16 // 这里不能简单地用自旋锁,否则会导致自旋过久,睡眠锁比较好
17 // 其他进程用完这个内存块之后,就会调用brelse,其中会wakeup这些睡眠者
18 // 谁先第一个谁就可以返回
19 acquiresleep(&b->lock);
20 return b;
21 }
22 }
23
24 // 到这里的时候说明这个block没有被缓存,这个时候得先分配一个buffer给他
25 uint minticks = ticks;
26 struct buf *victim = 0;
27
28 // 双向链表,回到原点说明遍历完毕
29 for (b = bcache.buckets[key].next; b != &bcache.buckets[key]; b = b->next)
30 {
31 if (b->refcnt == 0 && b->time <= minticks)
32 {
33 minticks = b->time;
34 victim = b;
35 // 这里不返回的原因是会找不到真正最小的
36 }
37 }
38 // 此时还需要判断是否找到了这样一个空闲的且是LRU的buffer
39 if (victim)
40 {
41 // 找到了就正常覆盖整个victim
42 // 标记这个buffer是属于哪个block的
43 victim->dev = dev;
44 victim->blockno = blockno;
45 victim->valid = 0; // 表明之前的数据是无效的
46 victim->refcnt = 1; // 有一个引用计数
47 release(&bcache.locks[key]);
48 // 这个buffer可以直接使用
49 // 但为了和之后的brelse中的release搭配还是使用sleep
50 acquiresleep(&victim->lock);
51 return victim;
52 }
53 else
54 {
55 // 说明这个bucket里没有空buffer了,只能从别的bucket里偷
56 for (int i = 0; i < NBUCKET; i++)
57 {
58 if (i == key)
59 continue;
60 acquire(&bcache.locks[i]);
61 minticks = ticks;
62 // 找出别的bucket里LRU的那个buffer,给他偷过来
63 for (b = bcache.buckets[i].next; b != &bcache.buckets[i]; b = b->next)
64 {
65 if (b->refcnt == 0 && b->time <= minticks)
66 {
67 minticks = b->time;
68 victim = b;
69 }
70 }
71 // 判断找没找到,找到继续,没找到就跳下一个bucket继续
72 if (!victim)
73 {
74 release(&bcache.locks[i]);
75 continue;
76 }
77 // 找到了之后就正常初始化先
78 victim->dev = dev;
79 victim->blockno = blockno;
80 victim->valid = 0; // 表明之前的数据是无效的
81 victim->refcnt = 1; // 有一个引用计数
82
83 // 下面逻辑比较绕,画个图就很好理解
84 // 从这个bucket里取出来放到自己的bucket里
85 victim->next->prev = victim->prev;
86 victim->prev->next = victim->next;
87 release(&bcache.locks[i]);
88
89 victim->next = bcache.buckets[key].next;
90 bcache.buckets[key].next->prev = victim;
91 bcache.buckets[key].next = victim;
92 victim->prev = &bcache.buckets[key];
93 release(&bcache.locks[key]);
94 acquiresleep(&victim->lock);
95 return victim;
96 }
97 }
98
99 // 如果上述过程都不能获取一个正确的buffer那就报错
100 panic("bget: no buffers");
101}
bget的任务是首先看这个buffer是不是被缓存了,如果是的话就直接返回,不是就创建新buffer,如果自己bucket中没有了,那就去别人的bucket中偷,偷的过程比较麻烦,毕竟有双向链表的操作,当然返回之前记得初始化。
更要记住哪些锁是用来保护哪些数据的:比如这里自己造的locks其实是保护这些buffer中除了data以外的数据,而buffer自己的lock是用来保护data的,保证只有一个人修改! 在使用过程中,如果获取了自己造的locks,那就只能改除了data以外的数据,而想改data只能获取buffer自己的lock,一定要一致,保证并发程序的正确性!
Lab9
Large files
目前fs只支持256+12个blocks,一个block 1kb,因此支持的文件比较小,因此该实验要求修改模块以支持更大的文件,实验要求都描述清楚了,需要实现二层链接即其中某个direct address要改成doubly indirect address。这个倒也没多难,无非是前11个用作直接块,第12个用作一重间接块,第13个用作二重间接块
- 修改NDIRECT等定义,修改inode和dinode定义,增加一些定义
1#define NDIRECT 11
2#define NINDIRECT (BSIZE / sizeof(uint))
3#define NDUBINDIRECT (256 * NINDIRECT)
4#define MAXFILE (NDIRECT + NINDIRECT + NDUBINDIRECT)
5
6// On-disk inode structure
7struct dinode {
8 short type; // File type
9 short major; // Major device number (T_DEVICE only)
10 short minor; // Minor device number (T_DEVICE only)
11 short nlink; // Number of links to inode in file system
12 uint size; // Size of file (bytes)
13 uint addrs[NDIRECT + 2]; // Data block addresses
14};
15
16// in-memory copy of an inode
17// 和block buffer一样的缓存机制
18struct inode {
19 uint dev; // Device number
20 uint inum; // Inode number
21 int ref; // Reference
22 // count,这里是内存中的引用计数,即在内存中引用此文件的指针数量,如果ref=0,则将其在内存中释放(写回到磁盘上)
23 struct sleeplock lock; // protects everything below here
24 int valid; // inode has been read from disk?
25
26 short type; // copy of disk inode
27 short major;
28 short minor;
29 short nlink; // 统计有多少文件目录引用到此inode以确定什么时候释放(硬盘上释放)
30 uint size; // 统计文件大小
31 uint addrs[NDIRECT + 2]; // 这个数组记录data blocks的number,毕竟inode大小是相同的
32};
- 修改bmap函数,使其支持两级块的索引,这里需要注意的是一定要记得brelse,难度不大
1static uint bmap(struct inode* ip, uint bn) {
2...
3
4 bn -= NINDIRECT;
5
6 if(bn < NDUBINDIRECT) {
7 // 找到第一层indirect address
8 if((addr = ip->addrs[NDIRECT + 1]) == 0)
9 ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
10 // 读取第一层数据
11 bp = bread(ip->dev, addr);
12 a = (uint*) bp->data;
13 if((addr = a[bn / 256]) == 0) {
14 a[bn / 256] = addr = balloc(ip->dev);
15 log_write(bp);
16 }
17 brelse(bp);
18 // 至此是最后一层
19 bp = bread(ip->dev, addr);
20 a = (uint*) bp->data;
21 if((addr = a[bn % 256]) == 0) {
22 a[bn % 256] = addr = balloc(ip->dev);
23 log_write(bp);
24 }
25 brelse(bp);
26 return addr;
27 }
28
29 panic("bmap: out of range");
30}
- 确保itrunc释放的时候也释放了
1void itrunc(struct inode* ip) {
2...
3 if(ip->addrs[NDIRECT + 1]) {
4 bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);
5 a = (uint*) bp->data;
6 for(j = 0; j < NINDIRECT; j++) {
7 if(a[j]) {
8 for(k = 0; k < NINDIRECT; k++) {
9 struct buf* bp2 = bread(ip->dev, a[j]);
10 uint* a2 = (uint*) bp2->data;
11 if(a2[k]) {
12 bfree(ip->dev, a2[k]);
13 }
14 brelse(bp2);
15 }
16 bfree(ip->dev, a[j]);
17 }
18 }
19 brelse(bp);
20 bfree(ip->dev, ip->addrs[NDIRECT + 1]);
21 ip->addrs[NDIRECT + 1] = 0;
22 }
23
24 ip->size = 0;
25 iupdate(ip);
26}
- 这个实验不难,仿照一级块套一层循环即可
Symbolic links
xv6原生支持的是硬链接,即不同名的文件却有相同的inode,而这里要支持的是软链接,即文件中保存的真正文件的path。
- 增加symlink系统调用,老套路了,这里不写
- 增加宏定义
1#define T_SYMLINK 4 // 软链接
2#define O_NOFOLLOW 0x100
- 在makefile中增加symlinktest
- 实现sys_symlink系统调用,这里主要思路是创建新文件,里面内容是链接的真正文件地址,
使用其他函数的时候必须注意返回的inode是否带锁,否则很容易死锁,一定要注意!
1uint64 sys_symlink(void) {
2 // input: target & path
3 char target[MAXPATH], path[MAXPATH];
4
5 if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
6 return -1;
7
8 begin_op();
9
10 struct inode* ip;
11 // 搞一个inode,类型是符号链接
12 // 内容则是真正链接的文件的路径,在此处即是target
13 // 在指定目录位置创建文件并返回inode,这里直接使用create函数,方便
14 // 注意,这里返回的ip是带锁的
15 if((ip = create(path, T_SYMLINK, 0, 0)) == 0) {
16 end_op();
17 return -1;
18 }
19 // 把真实文件path写入到此inode中
20 int res = writei(ip, 0, (uint64) target, 0, MAXPATH);
21
22 if(res != MAXPATH) {
23 end_op();
24 return -1;
25 }
26
27 iunlockput(ip);
28
29 end_op();
30 return 0;
31}
- open的时候也需要处理符号链接的情况,符号链接很容易成环,需要判断成环的情况!(注意锁的获取和释放,不要死锁!)
1uint64 sys_open(void) {
2 char path[MAXPATH];
3 int fd, omode;
4 struct file* f;
5 struct inode* ip;
6 int n;
7 int count = 0; // 计算寻找次数
8
9 if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)
10 return -1;
11
12 begin_op();
13
14 if(omode & O_CREATE) {
15 ip = create(path, T_FILE, 0, 0);
16 if(ip == 0) {
17 end_op();
18 return -1;
19 }
20 } else {
21 while(1) {
22 if((ip = namei(path)) == 0) {
23 end_op();
24 return -1;
25 }
26 ilock(ip);
27
28 if(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)) {
29 // 递归地打开该符号链接,这里套个循环得了
30 if(count > 10) {
31 iunlockput(ip);
32 end_op();
33 return -1;
34 }
35 int res;
36 res = readi(ip, 0, (uint64) path, 0, MAXPATH);
37 if(res != MAXPATH) {
38 iunlockput(ip);
39 end_op();
40 return -1;
41 }
42 iunlockput(ip);
43 count++;
44 } else {
45 break;
46 }
47 }
48
49 if(ip->type == T_DIR && omode != O_RDONLY) {
50 iunlockput(ip);
51 end_op();
52 return -1;
53 }
54 }
55
56...
57}
小结:这章的实验做起来感觉都有思路,被第二个实验的返回数据带不带锁坑了一把,感觉C++资源的生命周期什么的可能就是想解决这个问题。不过实话说这个还真设计的不错,对文件系统彻底了解了,回头再补一波jyy的讲解看看微软的文件系统
Lab10
mmap系统调用: void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); mmap主要有俩功能:
- 在进程间传输数据
- 将文件映射到内存中以减少传统的数据复制(磁盘-内存buffer-用户空间)
- 该实验只需要映射文件,假设addr为0,由内核决定真正的地址并返回,如果失败则返回0xffffffffffffffff;
- length来决定映射的大小,未必和文件大小相同;
- prot设置内存读写与执行的权限
- flags决定写的内容需不需要被写回文件
- fd是指定文件描述符
- offset假设为0
在该实验中只要求实现文件映射内存,猜测可能是先标记一下,之后访问就page fault然后一页页地从文件中读到内存映射部分(user space)而非buffer cache中
另一个需要实现的是munmap
1int munmap(void *addr, size_t length);
清理指定范围的map,有点free的意思了,如果有脏数据并且有正确的flags就回写到文件,并解除指定位置的映射。成功返回0,失败返回-1
也就是说这个实验是要添加这俩系统调用了。但还不是很懂mmap的作用,直接看了(这个人的)[https://zhuanlan.zhihu.com/p/458326109]。 传统的xv6系统调用需要经过以下几步:
read系统调用->usertrap内核处理->sys_read->fileread->readi,由readi把数据从硬盘搬到内核缓存再搬到用户空间。在此过程中每次的读写都需要read、write经历上述系统调用过程。mmap就直接把文件内容搬到了用户空间,可以直接操作,免得每次都要经过系统调用这几步。
- 添加mmap和munmap系统调用,添加mmaptest到makfile,老操作了,这里不写
- mmap把真正的加载推迟到了访问时,很类似lazy allocation、copy on write的操作,在实现之前需要想想,如果要在访问时再加载,则必须保存mmap的相关信息,在此处构造了一个结构体来保存这些信息:virtual memory area(vma),来保存虚拟内存分布相关信息
proc.h:
1#define VMASIZE 16
2struct vma {
3 int used;
4 uint64 addr;
5 int length;
6 int prot;
7 int flags;
8 int fd;
9 int offset;
10 struct file *file;
11};
12
13// Per-process state
14struct proc {
15 struct spinlock lock;
16
17 // p->lock must be held when using these:
18 enum procstate state; // Process state
19 struct proc *parent; // Parent process
20 void *chan; // If non-zero, sleeping on chan
21 int killed; // If non-zero, have been killed
22 int xstate; // Exit status to be returned to parent's wait
23 int pid; // Process ID
24
25 // these are private to the process, so p->lock need not be held.
26 uint64 kstack; // Virtual address of kernel stack
27 uint64 sz; // Size of process memory (bytes)
28 pagetable_t pagetable; // User page table
29 struct trapframe *trapframe; // data page for trampoline.S
30 struct context context; // swtch() here to run process
31 struct file *ofile[NOFILE]; // Open files
32 struct inode *cwd; // Current directory
33 char name[16]; // Process name (debugging)
34
35 struct vma vma[VMASIZE];
36};
这里vma数组的大小按照题目hints给16即可
- mmap实现就很简单了,只需要记录这些信息按兵不动,找一个没被用过的vma位置来保存自己的数据
1uint64 sys_mmap(void) {
2 uint64 error = 0xffffffffffffffff;
3
4 uint64 addr;
5 int length, prot, flags, fd, offset;
6 struct file *file; // 根据fd获取
7
8 if (argaddr(0, &addr) || argint(1, &length) || argint(2, &prot) || argint(3, &flags) || argfd(4, &fd, &file) ||
9 argint(5, &offset)) {
10 return error;
11 }
12
13 // 这三种情况同时出现必错
14 if (!file->writable && (prot & PROT_WRITE) && flags == MAP_SHARED) {
15 return error;
16 }
17
18 length = PGROUNDUP(length);
19
20 struct proc* p = myproc();
21 // 剩余可用空间不足
22 if ((p->sz + length) > MAXVA) {
23 return error;
24 }
25
26 // 从进程PCB可用VMA中找个空位置插进去
27 // 这里不直接分配
28 for (int i = 0; i < VMASIZE; i++) {
29 if (p->vma[i].used == 0) {
30 p->vma[i].used = 1;
31 p->vma[i].addr = p->sz; // 不管给的地址是什么,都从现有位置开始增长
32 p->vma[i].length = length;
33 p->vma[i].prot = prot;
34 p->vma[i].flags = flags;
35 p->vma[i].fd = fd;
36 p->vma[i].file = file;
37 p->vma[i].offset = offset;
38 // pin一下这个file
39 filedup(file);
40 p->sz += length;
41 return p->vma[i].addr;
42 }
43 }
44 return error;
45}
- 同时munmap也有思路,无非是unmap一部分或整体,找到对应的vma对其addr增加即可
1uint64 sys_munmap(void) {
2 uint64 addr;
3 int length;
4
5 struct proc *p = myproc();
6 struct vma *vma = 0;
7
8 if (argaddr(0, &addr) || argint(1, &length)) {
9 return -1;
10 }
11 addr = PGROUNDDOWN(addr);
12 length = PGROUNDUP(length);
13
14 // 找到对应的vma
15 for (int i = 0; i < VMASIZE; i++) {
16 if (addr >= p->vma[i].addr || addr < (p->vma[i].addr + p->vma[i].length)) {
17 vma = &p->vma[i];
18 break;
19 }
20 }
21 if (vma == 0) return -1;
22 // 这里很有趣,并没有全部都给删了,而是只删了申请的部分
23 if (vma->addr == addr) {
24 vma->addr += length;
25 vma->length -= length;
26 if (vma->flags & MAP_SHARED)
27 filewrite(vma->file, addr, length);
28 uvmunmap(p->pagetable, addr, length / PGSIZE, 1);
29 if (vma->length == 0) {
30 fileclose(vma->file);
31 vma->used = 0;
32 }
33 }
34 return 0;
35}
- 接下来就类似lazy allocation,cow等步骤了,在usertrap中增加page fault处理逻辑,主要思路就是根据发生错误的地址,找到对应vma,进而分配内存,从文件中读取数据并复制到新内存,mappages时给正确的标志位:
1void
2usertrap(void)
3{
4...
5 } else if((which_dev = devintr()) != 0){
6 // ok
7 } else if(r_scause() == 13 || r_scause() == 15) {
8 uint64 va = r_stval(); // 发生page fault的位置
9
10 if (va >= p->sz || va > MAXVA || PGROUNDUP(va) == PGROUNDDOWN(p->trapframe->sp)) {
11 p->killed = 1;
12 } else {
13 // 正常的处理步骤
14 struct vma *vma = 0;
15 for (int i = 0; i < VMASIZE; i++) {
16 // 找到这个地址对应的vma,即找到file
17 if (p->vma[i].used == 1 && va >= p->vma[i].addr && (va < p->vma[i].addr + p->vma[i].length)) {
18 vma = &p->vma[i];
19 break;
20 }
21 }
22
23 if (vma) {
24 // 地址的页面底部
25 va = PGROUNDDOWN(va);
26
27 uint64 offset = va - vma->addr;
28
29 uint64 mem = (uint64)kalloc();
30 if (mem == 0) {
31 p->killed = 1;
32 } else {
33 memset((void *)mem, 0, PGSIZE);
34 // 把数据从文件中读取出来,感觉很怪,不还是一样吗
35 ilock(vma->file->ip);
36 readi(vma->file->ip, 0, mem, offset, PGSIZE);
37 iunlock(vma->file->ip);
38 // 设置权限位
39 int flag = PTE_U;
40 if (vma->prot & PROT_READ) flag |= PTE_R;
41 if (vma->prot & PROT_WRITE) flag |= PTE_W;
42 if (vma->prot & PROT_EXEC) flag |= PTE_X;
43
44 if (mappages(p->pagetable, va, PGSIZE, mem, flag) != 0) {
45 kfree((void *)mem);
46 p->killed = 1;
47 }
48 }
49 }
50
51 }
52 } else {
53 printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
54 printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
55 p->killed = 1;
56 }
57...
58}
- 与lazy allocation和cow类似,在uvmunmap和uvmcopy两个函数中删除panic,因为此时页面尚未被加载到page table,倒也不能直接panic
1void
2uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
3{
4 uint64 a;
5 pte_t *pte;
6
7 if((va % PGSIZE) != 0)
8 panic("uvmunmap: not aligned");
9
10 for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
11 if((pte = walk(pagetable, a, 0)) == 0)
12 panic("uvmunmap: walk");
13 if((*pte & PTE_V) == 0)
14 continue;
15 // panic("uvmunmap: not mapped");
16 if(PTE_FLAGS(*pte) == PTE_V)
17 panic("uvmunmap: not a leaf");
18 if(do_free){
19 uint64 pa = PTE2PA(*pte);
20 kfree((void*)pa);
21 }
22 *pte = 0;
23 }
24}
25
26int
27uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
28{
29 pte_t *pte;
30 uint64 pa, i;
31 uint flags;
32 char *mem;
33
34 for(i = 0; i < sz; i += PGSIZE){
35 if((pte = walk(old, i, 0)) == 0)
36 panic("uvmcopy: pte should exist");
37 if((*pte & PTE_V) == 0)
38 continue;
39 // panic("uvmcopy: page not present");
40 pa = PTE2PA(*pte);
41 flags = PTE_FLAGS(*pte);
42 if((mem = kalloc()) == 0)
43 goto err;
44 memmove(mem, (char*)pa, PGSIZE);
45 if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
46 kfree(mem);
47 goto err;
48 }
49 }
50 return 0;
51
52 err:
53 uvmunmap(new, 0, i / PGSIZE, 1);
54 return -1;
55}
- 在fork和exit系统调用部分也需要处理,fork的时候要复制vma数组,exit的时候要回写数据到文件(如果有标志位的话)
1int
2fork(void)
3{
4...
5 np->state = RUNNABLE;
6
7 for(i = 0; i < VMASIZE; i++) {
8 if(p->vma[i].used){
9 memmove(&(np->vma[i]), &(p->vma[i]), sizeof(p->vma[i]));
10 filedup(p->vma[i].file);
11 }
12 }
13
14 release(&np->lock);
15
16 return pid;
17}
18
19void
20exit(int status)
21{
22 struct proc *p = myproc();
23
24 if(p == initproc)
25 panic("init exiting");
26
27 // Close all open files.
28 for(int fd = 0; fd < NOFILE; fd++){
29 if(p->ofile[fd]){
30 struct file *f = p->ofile[fd];
31 fileclose(f);
32 p->ofile[fd] = 0;
33 }
34 }
35
36 for(int i = 0; i < VMASIZE; i++) {
37 if(p->vma[i].used) {
38 if(p->vma[i].flags & MAP_SHARED)
39 filewrite(p->vma[i].file, p->vma[i].addr, p->vma[i].length);
40 fileclose(p->vma[i].file);
41 uvmunmap(p->pagetable, p->vma[i].addr, p->vma[i].length/PGSIZE, 1);
42 p->vma[i].used = 0;
43 }
44 }
45...
46}
小结:之前mmap完全理解不了,这下感觉也是虚拟内存的妙用,虚拟化才是真正的神啊。这样一想,java调用dll的jna可能也是相同的操作,把库加载,然后俩进程执行,中间部分数据共享。头文件该加还是得加,不然会出错,如果可以的话可以用sh脚本来统一添加头文件和#pragma once。brk分配的内存只能等高位内存释放后才能释放,mmap分配的内存可以单独释放,当然释放是以页为单位。
Lab11
给e1000网卡加驱动,说实话本来以为是让人了解一下网络,没想到只是写个驱动,大概理解怎么写,但实在不想看这个datasheet了。
首先需要了解,网卡硬件收到数据后会通过DMA把数据放到内存指定位置,而发送也是通过到指定位置找数据发送,这些位置以及控制的指令都是通过读写内存映射的寄存器来做到的。以发送为例:
1struct mbuf {
2 struct mbuf *next; // the next mbuf in the chain
3 char *head; // the current start position of the buffer
4 unsigned int len; // the length of the buffer
5 // 分配的页面是4kb,但这里只能用上mbuf大小的内存,2kb多一点,因此在此处head指向的就是buf中可用内存!
6 char buf[MBUF_SIZE]; // the backing store
7};
8
9// [E1000 3.2.3]
10struct rx_desc
11{
12 // 存储接收数据的地址
13 uint64 addr; /* Address of the descriptor's data buffer */
14 // 已经使用的长度
15 uint16 length; /* Length of data DMAed into data buffer */
16 // 校验和
17 uint16 csum; /* Packet checksum */
18 uint8 status; /* Descriptor status */
19 uint8 errors; /* Descriptor Errors */
20 uint16 special;
21};
22
23
24#define RX_RING_SIZE 16
25// 循环数组用以存储真正要放数据的空间的地址
26static struct rx_desc rx_ring[RX_RING_SIZE] __attribute__((aligned(16)));
27// 注意到上面需要一个空间,这里多半就是了
28static struct mbuf *rx_mbufs[RX_RING_SIZE];
其中mbuf是真正存储数据的地方,rxdesc只不过是保存这些地址。根据hints和网上代码,这个lab的做法如下:
- e1000_transmit
1int
2e1000_transmit(struct mbuf *m)
3{
4 //
5 // Your code here.
6 //
7 // the mbuf contains an ethernet frame; program it into
8 // the TX descriptor ring so that the e1000 sends it. Stash
9 // a pointer so that it can be freed after sending.
10 //
11
12 // 真正存数据的位置是mbuf,这里需要做的是把存了需要发送的数据的mbuf的地址放入空闲的发送位置里
13 // 而运行完毕之后就需要释放该mbuf
14
15 acquire(&e1000_lock);
16
17 uint32 r_index = regs[E1000_TDT];
18
19 // 检查是否满了
20 if ((tx_ring[r_index].status & E1000_TXD_STAT_DD) == 0) {
21 release(&e1000_lock);
22 return -1;
23 }
24
25 // 已经发送的可以释放了
26 if (tx_mbufs[r_index]) {
27 mbuffree(tx_mbufs[r_index]);
28 }
29
30 // 原有的位置填上正确的需要传输的mbuf
31 tx_ring[r_index].addr = (uint64) m->head;
32 tx_ring[r_index].length = (uint64) m->len;
33 tx_ring[r_index].cmd = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP;
34
35 tx_mbufs[r_index] = m;
36 regs[E1000_TDT] = (regs[E1000_TDT] + 1) % TX_RING_SIZE;
37 release(&e1000_lock);
38 return 0;
39}
- e1000_recv
1static void
2e1000_recv(void)
3{
4 //
5 // Your code here.
6 //
7 // Check for packets that have arrived from the e1000
8 // Create and deliver an mbuf for each packet (using net_rx()).
9 //
10
11 // 网卡会用DMA的方式把数据放到合适的位置
12 // 之后产生中断,进入该函数,该函数主要负责采用net_rx处理mbuf的数据
13 // 要记得分配新的mbuf,原来的mbuf应该是给net_rx使用了
14 while (1) {
15 // 获取下标
16 uint32 r_index = (regs[E1000_RDT] + 1) % RX_RING_SIZE;
17
18 if ((rx_ring[r_index].status & E1000_RXD_STAT_DD) == 0) {
19 return;
20 }
21 rx_mbufs[r_index]->len = (uint32)rx_ring[r_index].length;
22 if (rx_mbufs[r_index]) {
23 // 此时该指针的负责人被转向net_rx,由其负责释放,同时也避免了复制
24 net_rx(rx_mbufs[r_index]);
25 }
26 rx_mbufs[r_index] = mbufalloc(0);
27 rx_ring[r_index].addr = (uint64)rx_mbufs[r_index]->head;
28 rx_ring[r_index].status = 0;
29 regs[E1000_RDT] = r_index;
30 }
31}
这个实验感觉出的一般,重点并非网络而是驱动的编写,重点我倒是掌握了,懒得去读驱动手册了
参考
- 网友网站1
- csdiy的介绍
- 中文翻译
- 环境搭建、调试以及代码跳转
- 课程官网以及视频
- 阿苏EEer,也是这个UP主的,更正经一点
- cactus-agenda-c84.notion.site,对课本有详细的解释